We tripped over recently on our understanding of Microsoft SQL Server’s T-SQL LEN function. The following conversation encapsulates in a nutshell what any sensible developer would assume about the function.
@marcdurdin I guess the answer is, removing the line would give the same result. Right? 🙂
— S Krupa Shankar (@tamil) April 23, 2013
Now, I wouldn’t be writing this blog post if that was the whole story. Because, like so many of these things, it’s not quite that simple.
Originally, we were using RIGHT(string, LEN(string) – 2) to trim two characters off the front of our string. Or something like that. Perfectly legitimate and reasonable, one would think. But we were getting strange results, trimming more characters than we expected.
It turns out that T-SQL’s LEN function does not return the length of the string. It returns the length of the string, excluding trailing blanks. That is, excluding U+0020, 0x20, 32, ‘ ‘, or whatever you want to call it. But not tabs, new lines, zero width spaces, breaking or otherwise, or any other Unicode space category characters. Just that one character. This no doubt comes from the history of the CHAR(n) type, where fields were always padded out to n characters with spaces. But today, this is not a helpful feature.
Of course, RIGHT(string) does not ignore trailing blanks
But here’s where it gets really fun. Because a post about strings is never complete until you’ve done it in Unicode. Some pundits suggest using DATALENGTH to get the actual length of the string. This returns the length in bytes, not characters (remember that NCHAR is UTF-16, so 2 bytes per character… sorta!). Starting with SQL Server 2012, UTF-16 supplementary pairs can be treated as a single character, with the _SC collations, so you can’t even use DATALENGTH*2 to get the real length of the string!
OK. So how do you get the length of a string, blanks included, now that we’ve established that we can’t use DATALENGTH? Here’s one simple way:
SET @realLength = LEN(@str + ‘.’) – 1
Just to really do your head in, let’s see what happens when you use LEN with a bunch of garden variety SQL strings. I should warn you that this is a display artefact involving the decidedly unrecommended use of NUL characters, and no more, but the weird side effects are too fun to ignore.
First, here’s a set of SQL queries for our default collation (Latin1_General_CI_AS):
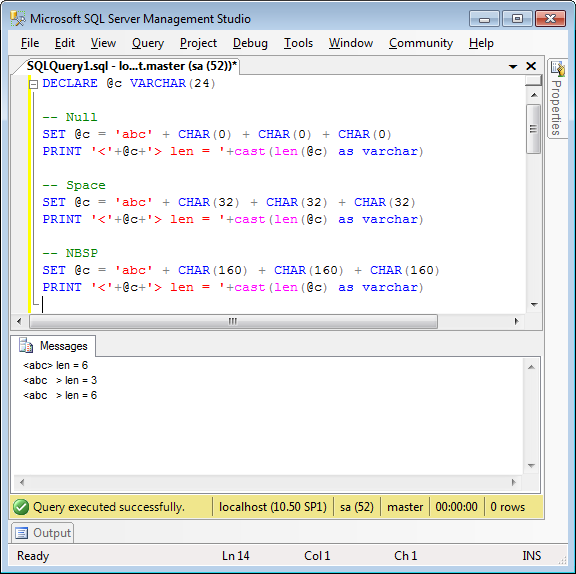
Note the output. Not exactly intuitive! Now we run the Unicode version:
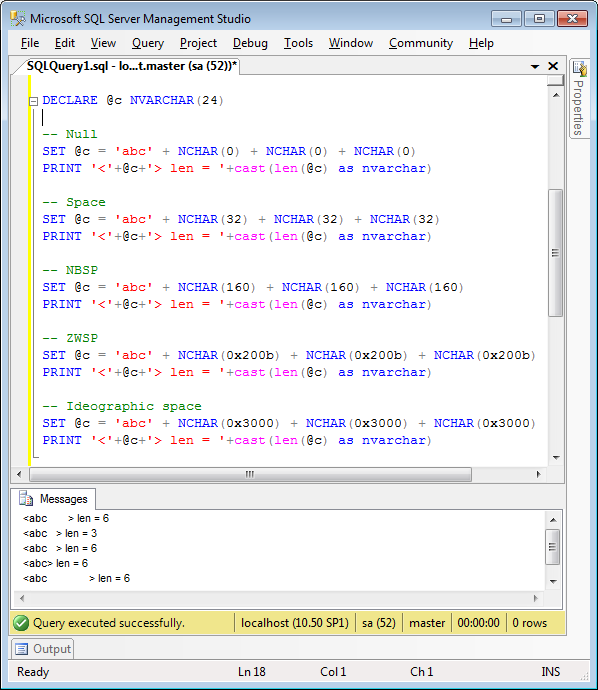
Not quite as many gotchas in that one? Or are there? Notice how the first line shows a wide space for the three NUL characters — but not quite as wide as the Ideographic space…
Now here’s where things go really weird. Running in Microsoft’s SQL Server Management Studio, I switch back to the first window, and, I must emphasise, without running any queries, or making any changes to settings, take a look at how the Messages tab appears now!
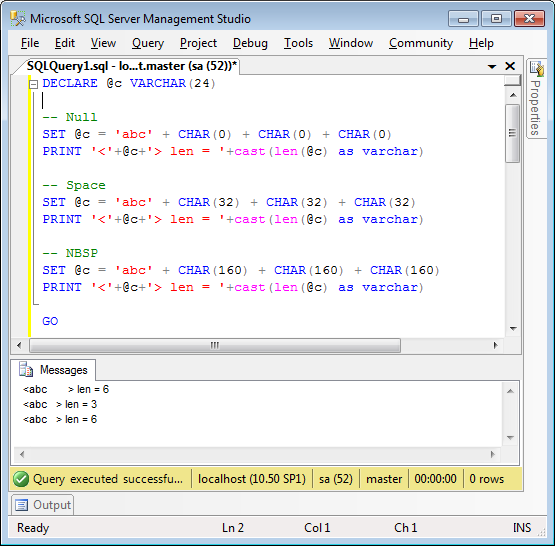
That’s right, the first line in the messages has magically changed! The only thing I can surmise is that switching one window into Unicode output has affected the whole program’s treatment of NUL characters. Let that be a warning to you (and I haven’t even mentioned consuming said NULs in C programs).