Recent podcast
I was recently privileged to be a guest on Scott Hanselman’s Hanselminutes podcast. It was great to talk about the history of Keyman and how it solved real problems for us 20+ years ago. But afterwards I realised I hadn’t really described what sorts of problems Keyman solves today and why it is still relevant.
So this post is that story.
Note: I’ve put this on my personal blog rather than the Keyman blog because it’s full of my own personal opinions. There’s lots of useful content on the Keyman blog as well!
The elevator pitch – and why I always struggled with it
A common story around venture capitalists and tech startups is that you have to have an amazing elevator pitch, the idea that within about 20-30 seconds, you can sell a problem and its solution to a person just begging to give you great wads of cash. And if you can’t describe the problem in 20 seconds then you probably don’t understand it yourself.
With all due respect, that might be fine for selling package drones or IoT nerf guns, but there are plenty of hard problems out there that cannot be understood in 20 seconds.
I think keyboard input for the world’s writing systems is one of those problems. For many people growing up with limited contact with Asian writing systems, they will look pretty and exotic. But that’s about the extent of it.
So, let’s imagine you and I are in an elevator, and just as you ask me to explain the benefit of Keyman to you, the power goes out and the elevator lurches to a halt. Now you are stuck with me and I can give you the extended elevator pitch!
An illustration from Khmer
Khmer is the national language of Cambodia, a small nation in South East Asia, home of one of the world’s ancient wonders, Angkor Wat.

Here’s a couple of samples of Khmer text. The first is a photo of an inscription from Angkor Wat.

This second image shows two common styles for writing Khmer, as computer fonts:

In a little bit, I’ll dig into how the writing system is used on computer. The script is beautiful, and it is complex, and it has a long and interesting history.
But first, I would like to tell you a story. I recently learned about an effort by a group of Cambodian linguists to revise and prepare a new edition of a Khmer language dictionary. The current “gold standard” Khmer dictionary, compiled by Samdech Porthinhean Chuon Nath, has not been updated since 1967. So a new edition is very much needed.
A number of different people have been involved in typing up entries for the dictionary. In the process, they discovered a problem: some entries which looked identical on screen were actually encoded differently in the computer. This meant that they were unable to consistently search for words, or even sort their dictionary correctly.
How had this happened? This happened because it is possible to type Khmer words in a number of different ways and get identical output on the screen. And I don’t mean by using different input methods, either. I mean with the standard Khmer keyboard layouts supplied with all major operating systems, desktop and mobile.
The Khmer Script
In this post, I won’t get too technical with lots of references to Unicode encodings. Instead, I’m trying to illustrate the issues from the point of view of a user, who shouldn’t need to worry about those details.
How would we go about typing a Khmer word? I’ve picked a famous Khmer word for us to start with:

This is the word ខ្មែរ /kmae/, Khmer, which is the name of the language and the people.
So, with the standard Khmer keyboard, how do you type this word?

Let’s imagine you had this word on a piece of paper and a standard Khmer keyboard in front of you. We can tell that it’s made up of a group of characters and some sort of diacritic marks.
![]()
Start with the first shape. It looks like a ![]() symbol and a
symbol and a ![]() diacritic mark. But the two marks belong together and make up a vowel sound, which we can find on the [SHIFT]+[E] key:
diacritic mark. But the two marks belong together and make up a vowel sound, which we can find on the [SHIFT]+[E] key:

Let’s go with that.

Next we have the ![]() character and the
character and the ![]() diacritic mark. The first bit is easy enough to find, on the [X] key.
diacritic mark. The first bit is easy enough to find, on the [X] key.

![]()
But that second bit? Okay, you won’t find that printed on a key cap. Fortunately, those using the Khmer keyboard tend to know their writing system. The ![]() character is a form of the
character is a form of the ![]() /m/ consonant used when it is the second letter in a consonant cluster. It is called a ជើង /cəəŋ/ letter in Khmer. This means leg or foot, base or support. (Diversion: The Unicode charts call them COENG consonants. I bet you read that as CO-ENG, didn’t you. I know I used to!)
/m/ consonant used when it is the second letter in a consonant cluster. It is called a ជើង /cəəŋ/ letter in Khmer. This means leg or foot, base or support. (Diversion: The Unicode charts call them COENG consonants. I bet you read that as CO-ENG, didn’t you. I know I used to!)
Okay, that’s all very interesting but how does one type these cəəŋ consonants? Well, the Unicode encoding standard added a special control character that’s not part of the writing system, called a KHMER SIGN COENG (U+17D2), just to support these letters. This is typed with a [J] key on the standard keyboard. Now we’re getting somewhere. So we’ll need to type [J] [M] to get that ![]() appearing under the
appearing under the ![]() .
.
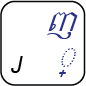

Now before we go any further, this magic sign is a problem. It’s a problem because now the user has to know something about the way their text is encoded in order to type it. It’s not a particularly hard thing to learn, but it isn’t obvious. And this is one of the easier things that a native Khmer speaker needs to learn in order to type their own language.
![]()
The last letter is easy enough. Here it is on the [R] key.

The full sequence, first try
So the full sequence is: [SHIFT]+[E] [X] [J] [M] [R].
Let’s go ahead and type it.
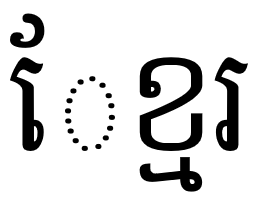
Ugh. Where did that dotted circle come from?
The dotted circle is a visual hint. It tells us that the vowel ![]() is written before the consonant it is attached to, but that the encoding places it after.
is written before the consonant it is attached to, but that the encoding places it after.
Second try
Okay, so let’s change it to [X] [SHIFT]+[E] [J] [M] [R].
Okay, that looks correct now.

Well, okay, it looks fine … but it’s not. In order to meet the Unicode ordering rules, the vowel has to be placed after the entire consonant cluster, just as if it was spoken.
Third time lucky
Let’s go back and fix that again. Here’s our final sequence. [X] [J] [M] [SHIFT]+[E] [R].
This is the correct sequence.
Now from a linguistic point of view most of this seems fairly logical, and it generally makes sense to users, once they learn it. But I hope this illustrates how some of these things are not obvious. If you haven’t been taught these rules, or if you do accidentally mis-type something, you won’t ever know about it.
It’s not hard to find examples that have a heap of different ways you could type them. For example:

At first glance that doesn’t look a lot more complex, right? However, we’ve found 14 different ways to encode this in Unicode, all of which look correct on Android devices! And if you repeat diacritic marks, then you can expand that to over 35 different combinations, all displayed identically! My colleagues and I wrote a paper on the problem. Can you imagine searching an online dictionary with these kinds of problems?
Other parts of the solution
Now I know some of you are going to be saying that this isn’t a problem that is unique to Khmer. That it can be solved with post-processing and normalisation. And you are correct, this problem extends to many scripts. And some problems can be solved with normalisation. But I think Unicode normalisation is an appropriate solution only with correctly encoded data. Our goal is for data to be encoded correctly at the time it enters the system.
You might argue that Autocorrect-type technologies could help with this, and they certainly can. But again, Autocorrect is really targeted at spelling and word completion, not avoiding encoding issues. (The inconsistently available implementations of Autocorrect don’t help either).
Improved rendering engines could also give helpful visual feedback to users, alerting them to mistyped sequences.
But none of these negate the importance of what Keyman brings to the party.
Keyman: A Comprehensive Input Method Solution
![]() So what does Keyman bring to this party? None of the system supplied Khmer keyboards make any attempt to quality control the input – generally they just output a single character for a single key.
So what does Keyman bring to this party? None of the system supplied Khmer keyboards make any attempt to quality control the input – generally they just output a single character for a single key.
Given we have well defined, structured linguistic and encoding rules, we can leverage those in the input method and ensure that sequences that are invalid according to the specification just don’t make it into the text store.
The power of Keyman
Keyman can automatically reorder and replace input as you type. For our example, if you type a vowel before typing a KHMER COENG SIGN and a consonant, Keyman will transparently and instantly fix the order in your document, and you won’t even know.
![]()
You can try a Khmer keyboard which automatically solves these encoding issues online at https://keymanweb.com/?tier=alpha#km,Keyboard_khmer_angkor
That, in a nutshell, is the power of Keyman.
Keyman makes possible amazingly intuitive input for complex writing systems.
Keyman is open source and completely free.
Keyman keyboard layouts are defined with a clear and easy to understand keyboard grammar, so that anyone can write a keyboard layout for their language. The development tools include visual editors, interactive debuggers and automated testing to help you develop sophisticated keyboard layouts.
Keyman runs everywhere. A keyboard layout can deployed to Windows, macOS, iOS, Android, Linux and even as a Javascript web keyboard. The Keyman project has a repository of over 700 existing keyboard layouts, and more are added every week.
Version 10 of Keyman is about to hit Beta. Would you like to be involved?
Oh look, the power is back on. Elevator pitch over. Oh by the way, aren’t writing systems cool?
Great post Marc – I had no idea Keyman could do this (is it already setup to do this in Khmer?).
Thanks Nathan! Yes, Makara Sok has created a keyboard for Khmer that does a lot of this work with Keyman 10 at https://keyman.com/keyboards/khmer_angkor
Very cool!
Hi Marc,
Another quick question. Do you know of any OpenSource typing trainers that could easily be integrated with a Keyman keyboard (meaning so we can train people to use the Khmer keyboard layout)?
Thanks,
Nathan
Afraid not — it’s something I’d be keen to pursue. There is a lovely typing tutor for Thai that uses KeymanWeb, but it’s not open source and the author has had limited time to pursue it: learnthaiping.com
Working on building keyman package for first time. Have been asked by my supervisor here a Wycliffe Associates to see about getting the SUN(Symbolic Uniform Notation) loaded on the ipad. I have the keyboard file, 2 ttf files in a package ready to go. My reading tells me I need a kmp.inf and kmp.json file in this same keyman package to get it to load on ipad. Is this correct? Am I corrrect in thinking I can get a custom keyboard and custom font loaded on an ipad in Keyman? Any help you can provided would be greatly appreciated. This is my first go round learning the in and outs of Keyman. Wycliffe Associates. Orlando, Fl
Hi Richard,
You don’t need to manually create the kmp.inf/kmp.json – they are created by the compiler. You use Keyman Developer to create the package. More information at https://help.keyman.com/developer/13.0/guides/distribute/. A good place to ask questions is https://community.software.sil.org/c/keyman
This is way cool and informative indeed. Thanks very much for your long history of work on Keyman as a great tool for many users of many natural languages. Special thanks to you for your extra attention and insight on the Khmer writing systems!
Thank you for reading Vuthy!