Every now and then I receive a payment via PayPal. That’s not unusual, right? PayPal would send me an email notifying me of the payment, and I’d open up Outlook to take a look at it. All well and good. In the last week, however, something changed. When I clicked on any PayPal email, Outlook would take the best part of a minute to open the email, and what’s more, would freeze its user interface entirely while doing this. But this was only happening with emails from PayPal — everything else was fine.
Not good. At first I suspected an addin was mucking things up, so I disabled all the Outlook addins and restarted Outlook for good measure. No difference. Now I was getting worried — what if this was some unintended side-effect of some malware that had somehow got onto my machine, and it was targeting PayPal emails?
So I decided to do some research. I fired up SysInternals’ Process Monitor, set it up to show only Outlook in its filtering, and turned on the Process Monitor trace.
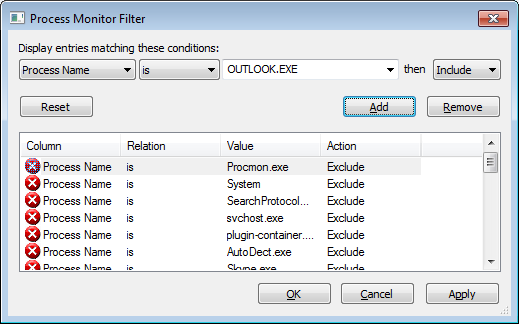 |
| Process Monitor filter window – filtering for OUTLOOK.EXE |
Then I went and clicked on a PayPal email. Waited the requisite time for the email to display, then went back to Process Monitor and turned off the trace. I added the Duration column to make it easier to spot an anomalous entry. This doesn’t always help but given the long delay, I was expecting some file or network activity to be taking a long time to run.
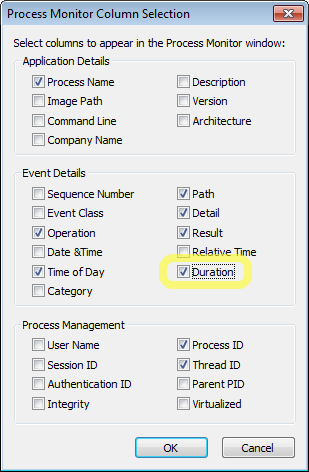 |
| Adding the Duration column |
Then scrolling up the log I quickly spotted the following entry. It had a duration of nearly 3 seconds which stood out like a sore thumb.
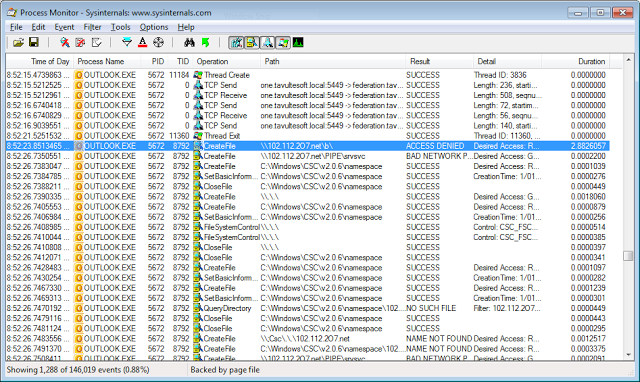 |
| The first offending entry |
This entry was a Windows Networking connection to connect to a share on the remote host \\102.112.2o7.net. This came back, nearly 3 seconds later, with ACCESS DENIED. Then there were a bunch of follow up entries that related to this, all in all taking over 30 seconds to complete. A quick web search revealed that this domain with its dubious looking name 102.112.2o7.net belongs to a well known web statistics company called Omniture. That took some of the load off my mind, but now I was wondering how on earth opening a PayPal email could result in Internet access when I didn’t have automatic downloads of pictures switched on.
 |
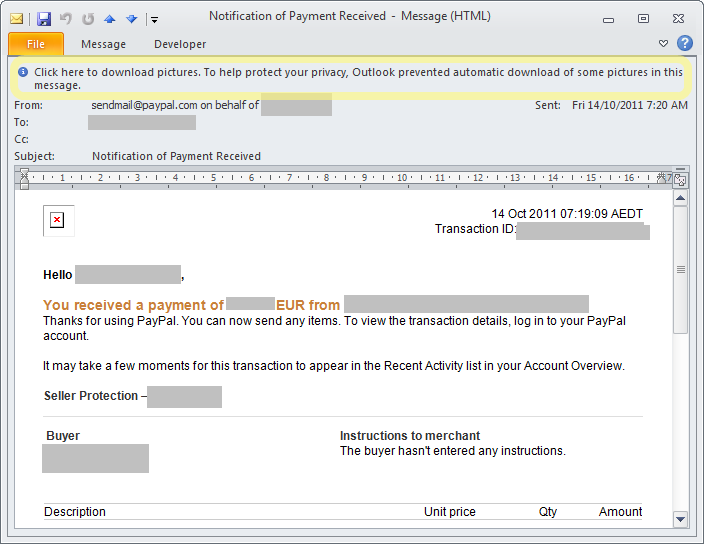
| One of the emails that caused the problem, redacted of course 🙂 |
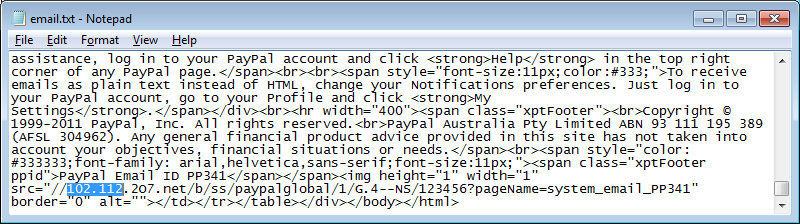
I opened the source of the PayPal HTML email and searched for “102.112“. And there it was.
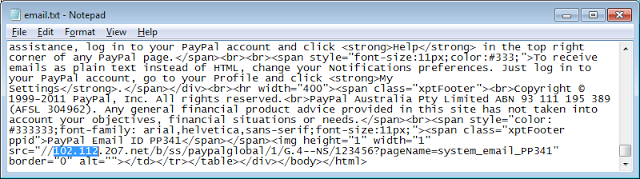 |
| The HTML email in notepad |
That’s a classic web bug. Retrieving that image of a 1×1 pixel size, no doubt transparent, with some details encoded in the URL to record my visit to the web page (or in this case, opening of the email):

What was curious about this web bug was the use of the “//” shorthand to imply the same protocol (e.g. HTTP or HTTPS) as the base page. That’s all well and good in a web browser, but in Outlook, the email is not being retrieved over HTTP. So Outlook interprets this as a Windows Networking address, and attempts a Windows Networking connection to the host instead, \\102.112.2o7.net\b….
At this point I realised this could be viewed as a security flaw in Outlook. So I wrote to Microsoft instead of publishing this post immediately. Microsoft responded that they did not view this as a vulnerability (as it does not result in system compromise), but that they’d pass it on to the Outlook team as a bug.
Nevertheless, this definitely has the potential of being exploited for tracking purposes. One important reason that external images are not loaded by default is to prevent third parties from being notified that you are reading a particular email. While this little issue does not actually cause the image to load (it is still classified as an external image), it does cause a network connection to the third party server which could easily be logged for tracking purposes. This network connection should not be happening.
So what was my fix? Well, I don’t really care about Omniture or whether PayPal get their statistics, so I added an entry in my hosts file to block this domain. Using an invalid IP address made it fail faster than the traditional use of 127.0.0.1:
0.0.0.0 102.112.2o7.net
And now my PayPal emails open quickly again.