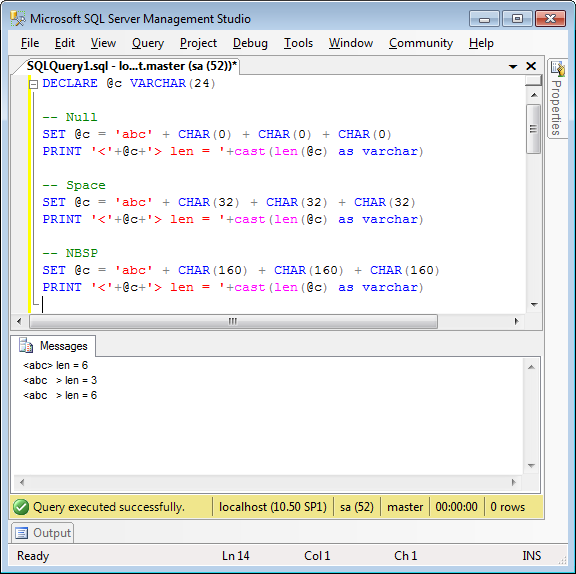
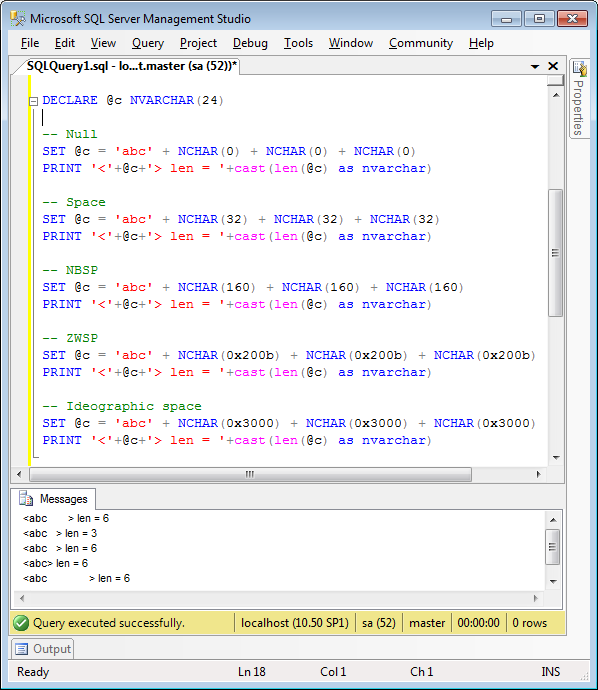
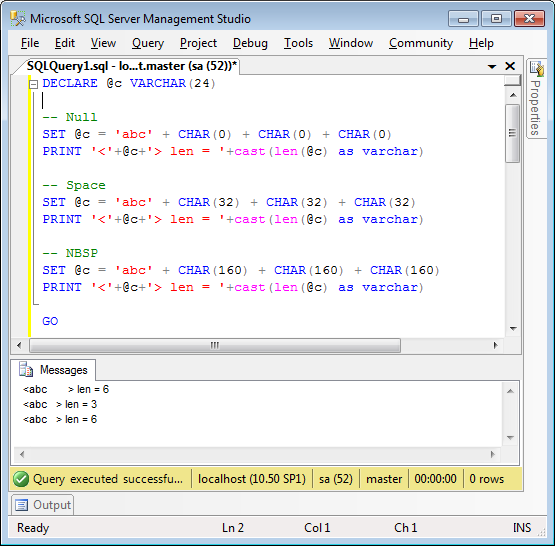
We just ran into a funny problem here, using a “tried and true” technique in SQL Server to concatenate strings. I use the quotes advisedly. This technique is often suggested on blogs and sites such as Stack Overflow, but we found out (by painful experience) that it is not to be relied on.
Update, 9 Mar 2016: Bruce Gordon from Webucator has turned this into a great little 5 minute video. Thanks Bruce! I don’t know anything much about Webucator, but they are doing some good stuff with creating well-attributed videos about blog posts such as this one and apparently they do SQL Server training.
The problem
So, given the following setup:
CREATE TABLE BadConcat (
BadConcatID INT NOT NULL,
Description NVARCHAR(100) NOT NULL,
SortIndex INT NOT NULL
CONSTRAINT PK_BadConcat PRIMARY KEY CLUSTERED (BadConcatID)
)
GO
INSERT BadConcat
SELECT 1, 'First Item', 1 union all
SELECT 2, 'Second Item', 2 union all
SELECT 3, 'Third Item', 3
GO
We need to concatenate those Descriptions. I have avoided fine tuning such as dropping the final comma or handling NULLs for the purpose of this example. This example shows one of the most commonly given answers to the problem:
DECLARE @Summary NVARCHAR(100) = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
ORDER BY ec.SortIndex
PRINT @Summary
And we get the following:
First Item, Second Item, Third Item, And that works fine. However, if we want to include a WHERE clause, even if that clause still selects everything, then we suddenly get something weird:
SET @Summary = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
PRINT @Summary
Now we get the following:
Third Item, What? What has SQL Server done? What’s happened to the first two items?
You’ll probably do what we did, which is to go through and make sure that you are selecting everything properly, which we are, and eventually come to the conclusion that “there must be a bug in SQL Server”.
The answer
It turns out that this iterative concatenation is unsupported functionality. Microsoft Knowledge Base article 287515 states:
You may encounter unexpected results when you apply any operators or expressions to the ORDER BY clause of aggregate concatenation queries.
Now, at first glance that does not directly apply. But we can extrapolate from that, as Microsoft developer support have done, in response to a bug report on SQL Server, to learn that:
The variable assignment with SELECT statement is a proprietary syntax (T-SQL only) where the behavior is undefined or plan dependent if multiple rows are produced
And again, in response to another bug report:
Using assignment operations (concatenation in this example) in queries with ORDER BY clause has undefined behavior. This can change from release to release or even within a particular server version due to changes in the query plan. You cannot rely on this behavior even if there are workarounds.
Some alternative solutions are given, also, in that second report:
The ONLY guaranteed mechanism are the following:
1. Use cursor to loop through the rows in specific order and concatenate the values
2. Use for xml query with ORDER BY to generate the concatenated values
3. Use CLR aggregate (this will not work with ORDER BY clause)
And the article “Concatenating Row Values in Transact-SQL” by Anith Sen goes through some of those solutions in detail. Sadly, none of them are as clean or as easy to understand as that original example.
Another example is given on Stack Overflow, which details how to safely use XML PATH to concatenate, without breaking on the XML special characters &, < and >. Applying that example into my problem code given above, we should use the following:
SELECT @Summary = (
SELECT ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
FOR XML PATH(''), TYPE
).value('.','varchar(max)')
PRINT @Summary
Voilà.
First Item, Second Item, Third Item,