I was recently landed with a real doozy of a support case: on some systems, under some circumstances, print jobs would be missing random characters. Like the following image:

As opposed to how it should appear:
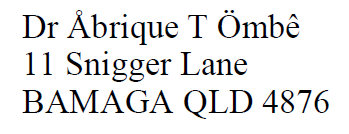
This example is missing the following letters: Å ê Ö q Q
In this particular example, you may be misled into thinking the problem is just with non-ASCII characters. But note that both upper case Q and lower case q are missing as well. Other example documents that we collected had no non-ASCII characters in them at all. I just used this example because it was one of the few we captured with fake data as opposed to real customer data.
This problem was not particularly printer dependent, and could be replicated (thank goodness!) with a PDF print driver. But the circumstances behind replicating the problem were a little strange: it only occurred, in the second document printed, when more than one print job was sent to the printer in quick succession. Some combinations of documents did not reflect the issue. If we sent the documents in the opposite order, they would often succeed. We were unable to replicate the problem on the printer in our office.
After many tries, I finally managed to replicate the issue on my development machine. Now I could break out the debugging tools and start some tracing.
I first used Process Monitor to capture details about temporary files in the print process. A lot of temporary files were generated. I examined many of them, but the files appeared intact: the problem was not reflected at this point in the print job.
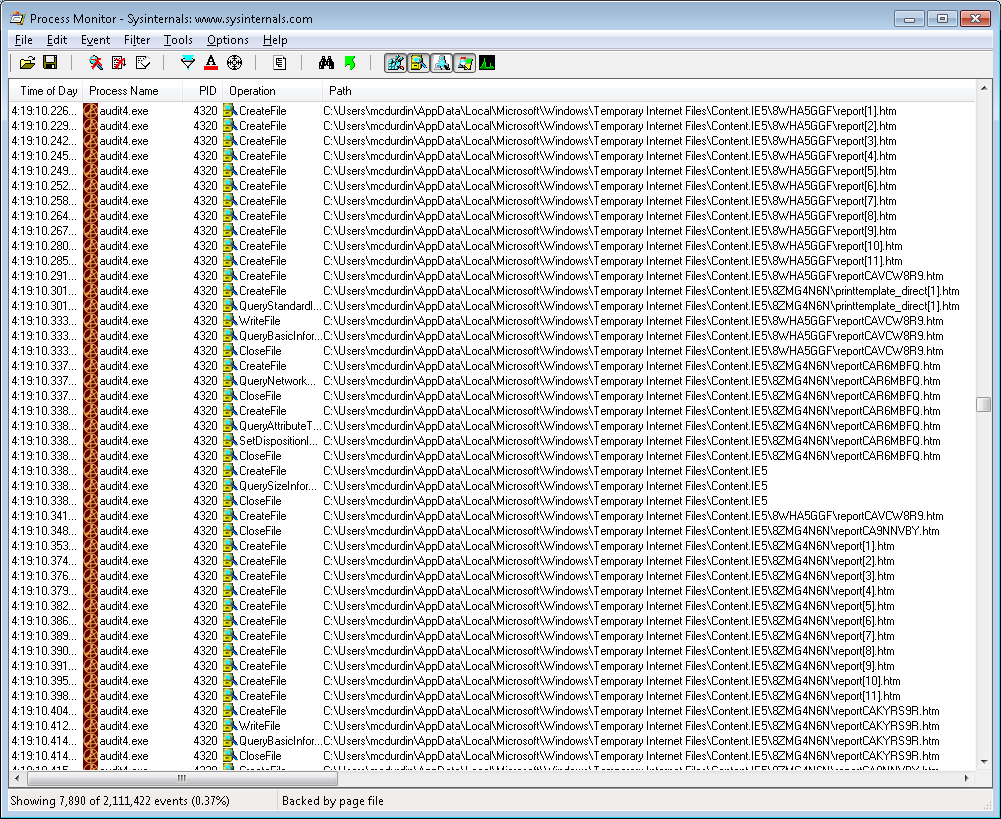
Next I attached a debugger to the process to try and figure out if I could spot any issues during the print itself. I put a breakpoint on GDI32!StartDocW and when that fired, enabled a breakpoint on GDI32!ExtTextOutW. This showed me all the strings that were being sent to the page during the print job.
Unfortunately, Internet Explorer 9 uses a process of printing to XPS and then converting that output to GDI commands for printing. The library which does the conversion from XPS to GDI used the flag ETO_GLYPH_INDEX when calling ExtTextOutW. This meant that examining the data in the debugger was pretty much a non-starter, without any easy to spot strings. So eventually I decided to log the whole lot to a text file, and pull the TrueType font glyph indices in the hope that the information in the TTF file would be sufficient to reconstruct the original text strings.
As it turned out, I was trivially able to match that data up to the XPS data by generating the report as an XPS. These are just a ZIP file with fonts, images and XML rendering data embedded. Easy to spelunk. It certainly seems that the correct glyph indices were being sent to the print engine. I matched these up between the data captured in the debugger as follows.
The text string:
Dr Åbrique T Ömbê
The XPS element:
Pulling out just the Glyph indices from the XPS element:
39;85;3;99;69;85;76;84;88;72;3;55;3;103;80;69;114
Converting those glyph indices to hexadecimal:
0027 0055 0003 0063 0045 0055 004c 0054 0058 0048 0003 0037 0003 0067 0050 0045 0072
Matching the data captured from ExtTextOutW:
233a4fe0 00550027 00630003 00550045 0054004c 233a4ff0 00480058 00370003 00670003 00450050 233a5000 abab0072
Note that the DWORDs are reversed because Intel uses little endian byte order (and abab is just garbage past the end of the array).
This suggested that the font data itself is being corrupted. Next, to check the font data in the .ps file as it is generated! Helpfully, PrimoPDF stores a .ps file in a temporary folder during the conversion to PDF. So it was just a matter of grabbing that file and looking at that. Well, of course PostScript and RTF are near the top of the list of painfully unreadable file formats, but a little trial and error (and GhostScript) found me the following:
779 1636 M [66 31 23 66 46 30 26 46 45 41 23 56 23 66 71 46 0]xS
Of which, 080B03380E0B1B3905090322033A0D0E3B should translate to Dr Åbrique T Ömbê:
08 0B 03 38 0E 0B 1B 39 05 09 03 22 03 3A 0D 0E 3B D r Å b r i q u e T Ö m b ê
Interestingly, the missing glyphs are all in the range 38-3B in this example. This line is identical in a version of the file that printed without errors, but the font data is quite different.
Right, so we know data corruption is occurring in the font data. But we knew that data corruption was the issue already. So where are we now? Have I accomplished anything by going down this track? Yes! I know now that it is happening in the conversion of an XPS document to GDI, in the print process. Given this and that it happens only when 2 documents are printed, it is almost certainly a threading issue in the XPS to GDI library.
Armed with that new-found knowledge, I set out to build a minimal test application. Here’s the very hacky test case I ended up with:
#include "stdafx.h"
int Print(LPWSTR inFile, LPWSTR outFile, LPWSTR printer);
int _tmain(int argc, _TCHAR* argv[]) {
if(argc < 2) {
printf("Usage: XpsThread Apartment|Multi [PathToXPSFiles] [Printer]\n");
return 1;
}
if(_wcsicmp(argv[1], L"Apartment") == 0)
CoInitializeEx(0, COINIT_APARTMENTTHREADED);
else
CoInitializeEx(0, COINIT_MULTITHREADED);
/* This assumes 2 files named 0.xps and 1.xps. No need to make more complex at this stage. */
WCHAR inFile[MAX_PATH], outFile[MAX_PATH];
PWCHAR printer = argc > 3 ? argv[3] : L"PrimoPDF";
for(int i = 0; i < 2; i++)
{
wsprintf(inFile, L"%s%s%d.xps", argc > 2 ? argv[2] : L"", argc > 2 ? (*(wcschr(argv[2],0)-1) == '\\' ? L"" : L"\\") : L"", i);
wsprintf(outFile, L"%s%s%d.ps", argc > 2 ? argv[2] : L"", argc > 2 ? (*(wcschr(argv[2],0)-1) == '\\' ? L"" : L"\\") : L"", i);
Print(inFile, outFile, printer);
}
getchar(); // Manually wait for print jobs to finish.
CoUninitialize();
// Examine the .ps files in GSview or whatever takes your fancy. The second file generated will often be corrupt if COINIT_MULTITHREADED is used.
return 0;
}
int Print(LPWSTR inFile, LPWSTR outFile, LPWSTR printer) {
IXpsPrintJobStream *docStream = NULL;
HRESULT hr;
hr = StartXpsPrintJob(printer, NULL, outFile, 0, 0, NULL, 0, NULL, &docStream, NULL);
if(SUCCEEDED(hr)) {
FILE *fp = _wfopen(inFile, L"rb");
BYTE buf[512];
int n = fread(buf, 1, 512, fp);
ULONG sz;
while(n > 0) {
docStream->Write(buf, n, &sz);
n = fread(buf, 1, 512, fp);
}
fclose(fp);
hr = docStream->Close();
if(SUCCEEDED(hr)) {
wprintf(L"Succeeded: %s\n", inFile);
return 0;
}
}
wprintf(L"Failed to print %s: %x\n", inFile, hr);
return 1;
}
It may have been a little hacky, but it proved the bug. It turns out, printing multiple documents at once with COM initialised with the flag COINIT_MULTITHREADED will consistently fail, even though that is the mode used in the example in MSDN.
Okay, so let’s take that information back to our application in Windbg, and see if we can find anything in MSHTML’s printing. I popped in a couple of breakpoints:
bp coinitializeex ".echo ---CoInitializeEx---; ~.; dd esp+8 L1; gc" bp gdi32!startdocw ".echo ---StartDocW---; ~.;"
The first would show me the thread ID and the COINIT flags issued every time CoInitializeEx was called. The second would break when StartDoc was called to start a print job, from the XPS printing code (XpsGdiConverter.dll). This would tell me the threading mode for the thread. And as I was now expecting, MSHTML uses COINIT_MULTITHREADED (= 00000000).
---CoInitializeEx--- . 2 Id: 1464.f80 Suspend: 1 Teb: 7efd7000 Unfrozen Start: mshtml!ShowModelessHTMLDialog+0x5460 (6dc0d50e) Priority: 0 Priority class: 32 Affinity: f 189ef0b4 00000000 ---StartDocW--- . 2 Id: 1464.f80 Suspend: 1 Teb: 7efd7000 Unfrozen Start: mshtml!ShowModelessHTMLDialog+0x5460 (6dc0d50e) Priority: 0 Priority class: 32 Affinity: f
Interestingly, when I was researching XPS printing in MSDN, I came across a page in the .NET Framework documentation which contains the following detail:
The three-parameter AddJob(String, String, Boolean) overload of AddJob must run in a single thread apartment whenever the Boolean parameter is false, which it must be when a non-XPSDrv printer is being used. However, the default apartment state for Microsoft .NET is multiple thread. This default must be reversed since the example assumes a non-XPSDrv printer
There are two ways to change the default. One way is to simply add the STAThreadAttribute (that is, “[System.STAThreadAttribute()]”) just above the first line of the application’s Main method (usually “static void Main(string[] args)”). However, many applications require that the Main method have a multi-threaded apartment state, so there is a second method: put the call to AddJob(String, String, Boolean) in a separate thread whose apartment state is set to STA with SetApartmentState. The example below uses this second technique.
This little detail is not in the Win32 XPS documentation. I can’t prove that this is the cause of the problem but it certainly seems suspicious that this goes wrong with MSHTML. I tried a very naughty test whereby I overrode the COINIT flags whenever CoInitializeEx was called (WinDbg: bp ole32!coinitializeex “ed esp+8 2; gc”), and the problem “went away” … it’s a nice finger-in-the-wind test but certainly not conclusive!
The problem does not occur on the printer in our office, because it is an XPSDrv printer. The problem only occurs with drivers that do not support XPS, because XPSDrv does not require apartment threading.
Anyway, I think it’s time to take this case to Microsoft. In the meantime, the safest workaround is to wait for the first print job to finish before starting a subsequent one. We’ll probably put that fix in for now, even though it makes the print tediously slow!
Hi,
Did you have any luck getting a fix from Microsoft?
We are still working with Microsoft on this issue. It has not been forgotten!
Would be very interested to read about any feedback you get from Microsoft about this. In my testing I haven’t found the apartment model to have any real effect, the same printing problem can be seen both using .NET/WPF running in an STA or the native API either STA or MTA. My best guess is that the problem actually occurs in the spooler when EMF is in use.
Still waiting on MS…
Can you tell me what printer your using in your office? We’re about to implement an application that suffers from this problem and do not want to downgrade to IE8 to fix our issue. And thought our vendor said there weren’t any printers that supported XPS. I was sceptical that none existed, and rightly so ans you have proof sitting 10s of feet from you.
Jeff, it’s a HP LaserJet P2055
FWIW, I don’t think this problem is as simple as mismatched threading models. I think that just highlights a race condition, somewhere in the XPS->GDI renderer.
Microsoft’s IE team have now confirmed the bug and reported that it is a problem in Windows, specifically the XPS components. A bug has been filed for the Windows team.
Marc, do you have a link/reference to the bug filed for Microsoft? Thanks!
Sorry, it was a support contract contact, so no public bug references. May have some more news shortly — we are currently testing a fix from Microsoft.
http://support.microsoft.com/kb/2853777
I am happy to announce that the missing characters have been found!: Microsoft have published the fix.