Delphi XE2 and later versions have a robust theming system that has a frustrating flaw: the client width and height are not reliably preserved when the theme changes the border widths for dialog boxes.
For forms that are sizeable this is not typically a problem, but for dialogs laid out statically this can look really ugly, as shown in this Stack Overflow question.
The problem in pictures
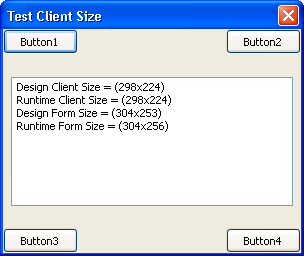
Here’s a little form, shown in the Delphi form designer. I’ve placed 4 buttons right in the corners of the form. I’m going to populate the Memo with notes on the form size at runtime.
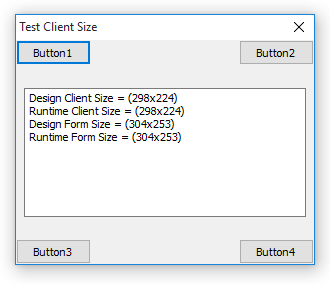
When I have no custom style set to the project (i.e. “Windows” style), I can run on a variety of platforms and see the buttons are where they should be. Shown here on Windows 10, Windows 7 and Windows XP (just because):
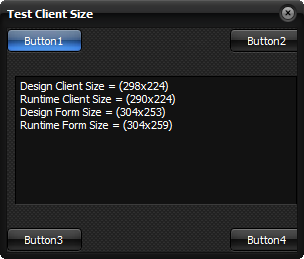
But when I apply a custom style to the project — I chose “Glossy” — then my dialog appears like so, instead:
You’ll note that the vertical is adjusted but the horizontal is not: Button2 and Button4 are now chopped off on the right. Because we are using themes, the form looks identical on all platforms.
For my needs, I found a workaround using a class helper, which can be applied to the forms which need to maintain their design-time ClientWidth and ClientHeight. This is typically the case for dialog boxes.
This workaround should be used with care as it has been designed to address a single issue and may have side effects.
It will trigger resize events at load time
Setting AutoScroll = true means that ClientWidth and ClientHeight are not stored in the form .dfm, and so this does not work.
It may not address other layout issues such as scaled elements scaling wrongly (I haven’t tested this).
type
TFormHelper = class helper for Vcl.Forms.TCustomForm
private
procedure RestoreDesignClientSize;
end;
procedure TfrmTestSize.FormCreate(Sender: TObject);
begin
RestoreDesignClientSize;
end;
{ TFormHelper }
procedure TFormHelper.RestoreDesignClientSize;
begin
if BorderStyle in [bsSingle, bsDialog] then
begin
if Self.FClientWidth > 0 then ClientWidth := Self.FClientWidth;
if Self.FClientHeight > 0 then ClientHeight := Self.FClientHeight;
end;
end;
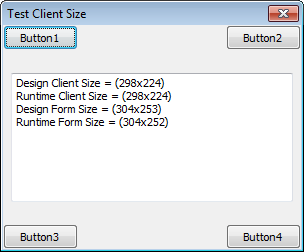
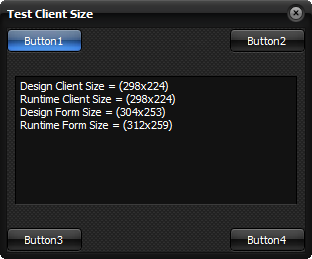
After adding in this little snippet, the form is now restored to its design-time size, like thus:
We just ran into a funny problem here, using a “tried and true” technique in SQL Server to concatenate strings. I use the quotes advisedly. This technique is often suggested on blogs and sites such as Stack Overflow, but we found out (by painful experience) that it is not to be relied on.
Update, 9 Mar 2016: Bruce Gordon from Webucator has turned this into a great little 5 minute video. Thanks Bruce! I don’t know anything much about Webucator, but they are doing some good stuff with creating well-attributed videos about blog posts such as this one and apparently they do SQL Server training.
The problem
So, given the following setup:
CREATE TABLE BadConcat (
BadConcatID INT NOT NULL,
Description NVARCHAR(100) NOT NULL,
SortIndex INT NOT NULL
CONSTRAINT PK_BadConcat PRIMARY KEY CLUSTERED (BadConcatID)
)
GO
INSERT BadConcat
SELECT 1, 'First Item', 1 union all
SELECT 2, 'Second Item', 2 union all
SELECT 3, 'Third Item', 3
GO
We need to concatenate those Descriptions. I have avoided fine tuning such as dropping the final comma or handling NULLs for the purpose of this example. This example shows one of the most commonly given answers to the problem:
DECLARE @Summary NVARCHAR(100) = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
ORDER BY ec.SortIndex
PRINT @Summary
And we get the following:
First Item, Second Item, Third Item,
And that works fine. However, if we want to include a WHERE clause, even if that clause still selects everything, then we suddenly get something weird:
SET @Summary = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
PRINT @Summary
Now we get the following:
Third Item,
What? What has SQL Server done? What’s happened to the first two items?
You’ll probably do what we did, which is to go through and make sure that you are selecting everything properly, which we are, and eventually come to the conclusion that “there must be a bug in SQL Server”.
You may encounter unexpected results when you apply any operators or expressions to the ORDER BY clause of aggregate concatenation queries.
Now, at first glance that does not directly apply. But we can extrapolate from that, as Microsoft developer support have done, in response to a bug report on SQL Server, to learn that:
The variable assignment with SELECT statement is a proprietary syntax (T-SQL only) where the behavior is undefined or plan dependent if multiple rows are produced
Using assignment operations (concatenation in this example) in queries with ORDER BY clause has undefined behavior. This can change from release to release or even within a particular server version due to changes in the query plan. You cannot rely on this behavior even if there are workarounds.
Some alternative solutions are given, also, in that second report:
The ONLY guaranteed mechanism are the following:
1. Use cursor to loop through the rows in specific order and concatenate the values
2. Use for xml query with ORDER BY to generate the concatenated values
3. Use CLR aggregate (this will not work with ORDER BY clause)
And the article “Concatenating Row Values in Transact-SQL” by Anith Sen goes through some of those solutions in detail. Sadly, none of them are as clean or as easy to understand as that original example.
Another example is given on Stack Overflow, which details how to safely use XML PATH to concatenate, without breaking on the XML special characters &, < and >. Applying that example into my problem code given above, we should use the following:
SELECT @Summary = (
SELECT ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
FOR XML PATH(''), TYPE
).value('.','varchar(max)')
PRINT @Summary
One of my dev machines has long had a weird anomaly where file operations in Explorer that should prompt for UAC, such as copying a file into C:\Program Files, would instead silently fail.
This led to all sorts of issues, from being unable to delete certain files — they’d just obstinately sit there, no matter how much I pressed that Del key — to trying to move folders containing a hidden Thumbs.db file and being unable to move the folder.
My UAC settings were the Windows defaults. Nothing weird these. So I’d always treated put this issue into my “too busy to solve this now” basket. The classic basket case. But today I finally got fed up.
After a quick search for the symptoms on Dr Google returned no results of significance, I decided I needed to trace the cause myself.
Process Monitor to the Rescue
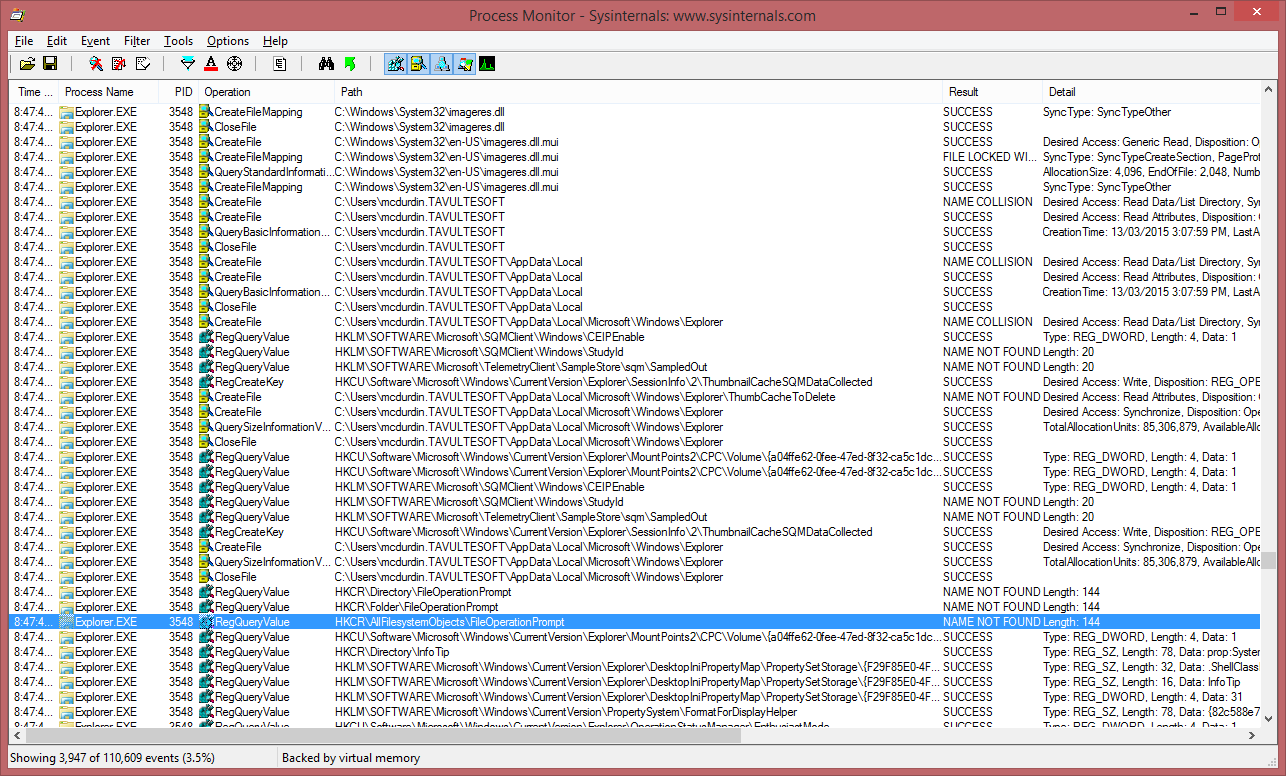
It was time to pull out Process Monitor out of my toolbox again! Process Monitor is a tool from the SysInternals Suite by Microsoft that monitors and logs details on a bunch of different operations on your computer. I use Process Monitor, Procmon for short, all the time to solve problems big and little. But for some reason, it hadn’t crossed my mind until today that I could apply Procmon to this problem.
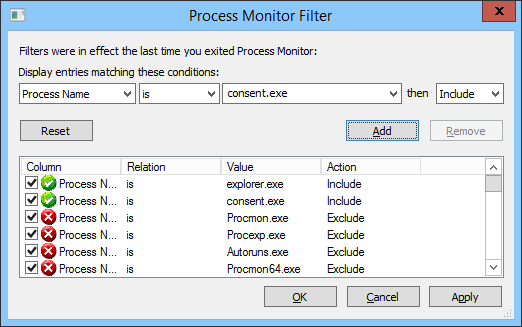
First, I configured Procmon to filter all events except for those generated by Explorer.exe and Consent.exe. I wasn’t sure if Consent.exe was involved in the problem (Consent.exe being the UAC elevation prompter), but it wouldn’t hurt to include it to start with. Note that all those Exclude filters are default filters setup by Procmon to exclude itself and its friends, removing that confusion from the logs.
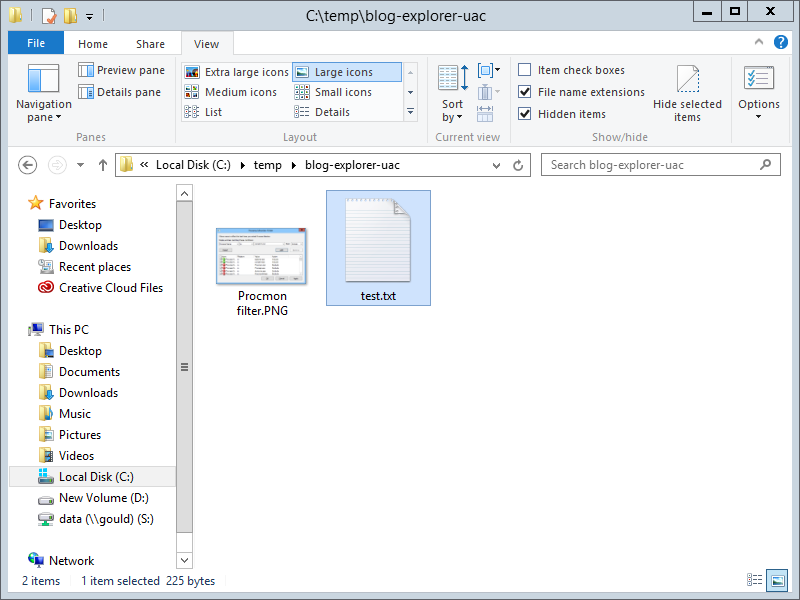
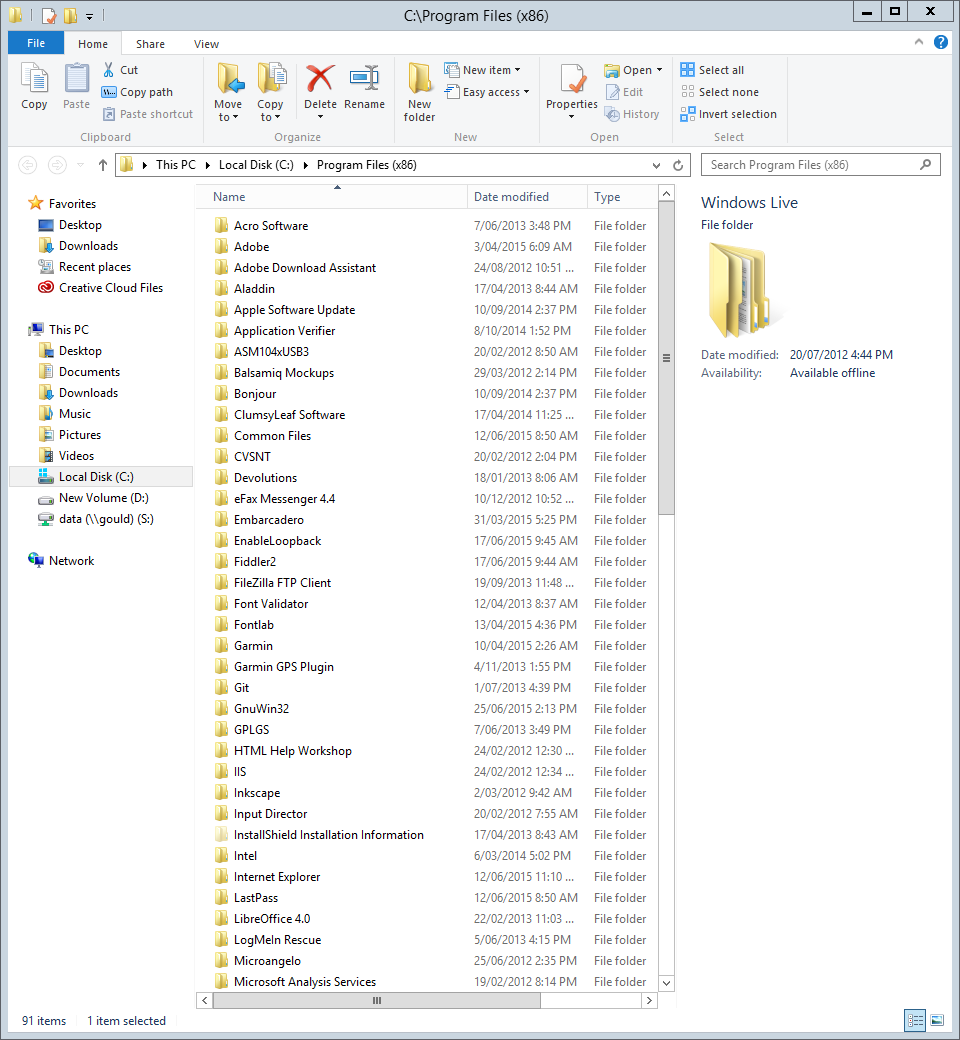
Then I went ahead and tried to copy a file into C:\Program Files (x86). It was just an innocent little text file, but Explorer of course acted like a Buckingham Palace Guard and silently and stolidly ignored its existence.
➔
I used the clipboard Ctrl+C and Ctrl+V to copy and paste (or attempt to paste) the file. I didn’t think the clipboard was at fault because all other UAC-required file operations also failed silently. I could have dragged and dropped, it would have had the same effect.
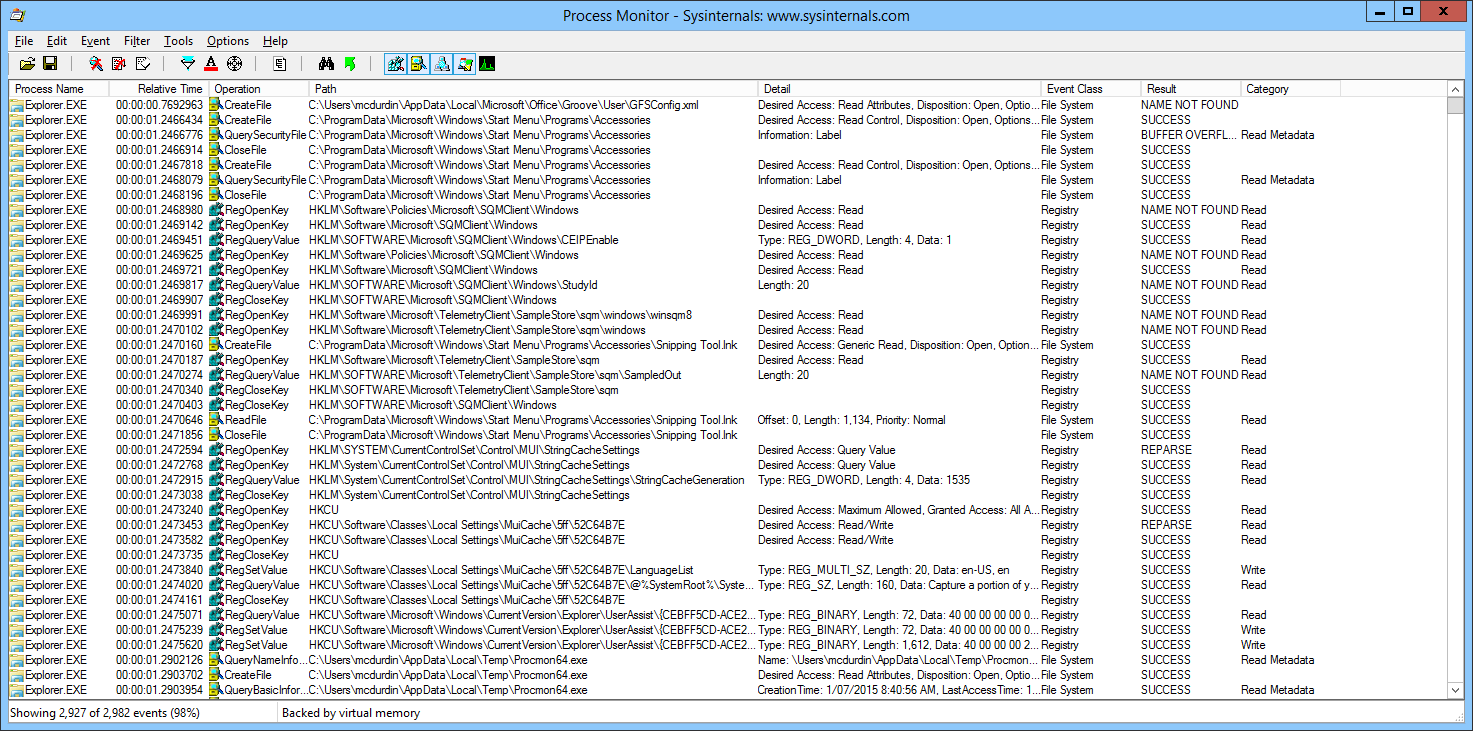
But now, with procmon, I had captured the communication that went on behind the scenes. All those secret coded winks and nose scratches that told Explorer to fob off any attempts to trigger a UAC prompt. Here’s what I was presented with in the Procmon log.
I searched for the name of my text file (test.txt), and used Procmon’s Highlight tool to highlight every reference to it in the Path column. This made it easy to spot nearby interactions that may have been related, even if they didn’t directly reference the test.txt file itself. You can see below two of the highlighted test.txt lines.
Because there was a lot going on, I filtered out a lot of Operations that I thought were not relevant, such as CloseFile, RegCloseKey, RegQueryKey, ReadFile and WriteFile, among others. This reduced the log considerably and made it easier to spot differences (my screen capture below shows the filtering after it was reset, however — I forgot to capture the filtered trace, sorry).
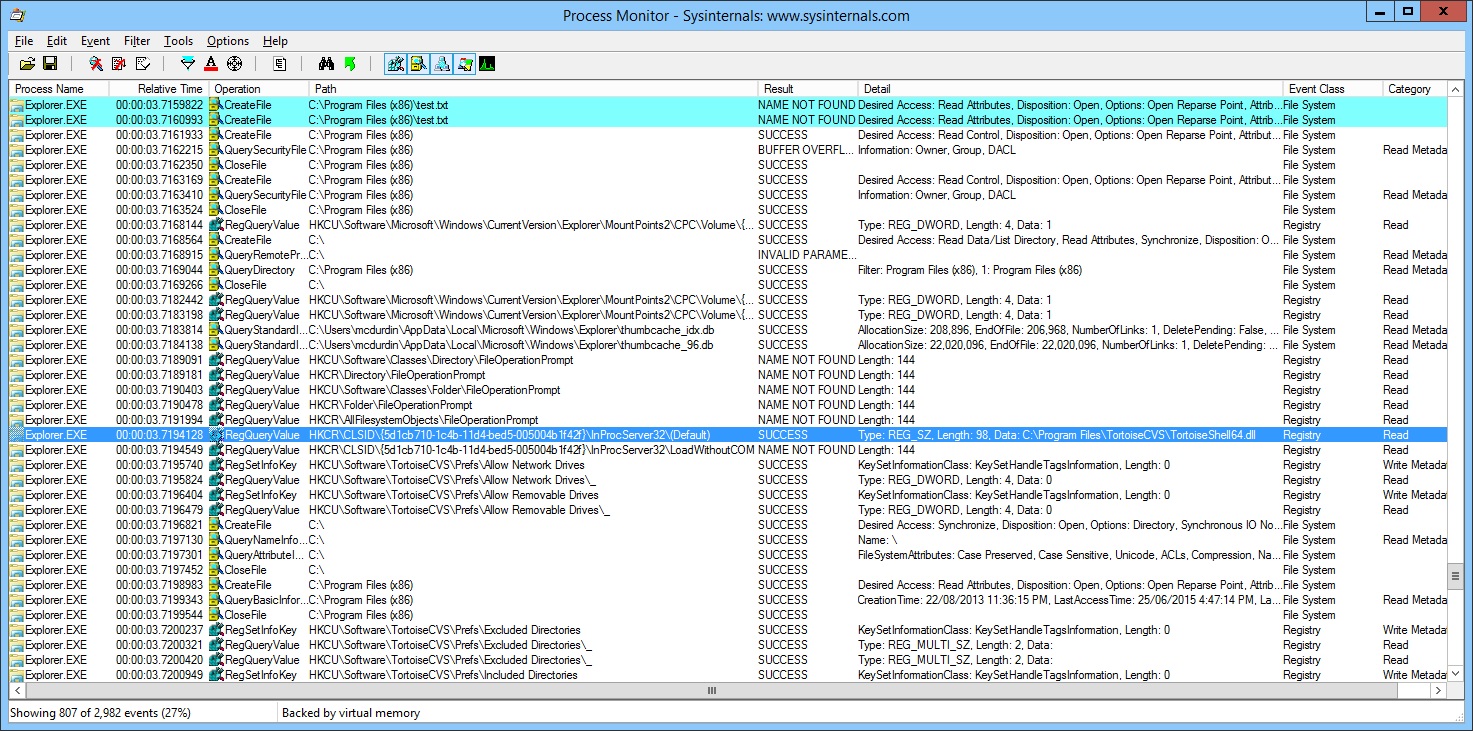
I decided to also capture a trace on a machine where UAC prompting worked. I then compared the two logs. After scrolling back and forth around the many references to test.txt, I saw that on my dev machine, there was an additional interaction, right before the point where the prompt dialog was presented:
That’s right, I had a program called TortoiseCVS installed on this machine which hooked into Explorer in a variety of ways. After the FileOperationPrompt references on my second machine, there was no reference to TortoiseCVS. Here’s what it looked like on the other machine:
That was the only visible difference of significance in the logs.
Now for those of you who just knee-jerked into “why on earth are you using CVS?!?”, calm down! This is a story, and I’m telling the story.
I decided that I didn’t really need TortoiseCVS installed and decided to try uninstalling it.
Sadly, uninstalling it required a reboot, no doubt to remove its old fashioned hooks into Explorer.
After the reboot, I tried to copy my innocent little text file again.
Success! I was now presented with the prompt I wanted!
Another case closed thanks to SysInternals Suite and Mark Russinovich!
We recently ran into a nasty little bug in the Delphi XE2 compiler, that arises with a complex set of conditions:
A record with a string property that has a get function;
A call to this getter that has a constant string appended to the result;
This result passed directly to another arbitrary function.
When these conditions are met (see code below for examples), the compiler generates code that crashes.
Reproducing the bug
The following program is enough to reproduce the bug.
program ustrcatbug;
type
TWrappedString = record
private
FValue: string;
function GetValue: string;
public
property Value: string read GetValue;
end;
{ TWrappedString }
function TWrappedString.GetValue: string;
begin
Result := FValue;
end;
function GetWrappedString: TWrappedString;
begin
Result.FValue := 'Something';
end;
begin
writeln(GetWrappedString.Value + ' Else');
end.
Looking at the last line of code from that sample in the disassembler, we see the following code:
The problem is that eax is not preserved through function calls with Delphi’s default register calling convention. And, as _UStrCat is a procedure, we can make no assumptions about the return value (which is passed in eax):
Upgrade to Delphi XE7 – this problem appears to be resolved, though I could not find a QC or RSP report relating to the bug when I searched. Moving to XE7 is not an option for us in the short term: too many code changes, too many unknowns.
Don’t use properties in records. This means changing code to call functions instead: no big deal for the Get, but annoying for the Set half of the function pair.
Patch around the problem by modifying UStrCat to return the address of the Dest parameter.
In the end, I wrote option (3) but we went with option (2) in our code base.
Because UStrCat is implemented in System.pas, it’s difficult to build your own version of the unit. One way to skin the option 3 UStrCat is to copy the implementation of UStrCat and its dependencies (a bunch of memory and string manipulation functions), and monkeypatch at runtime.
In the copied functions, we need to preserve eax through the function calls. This results in the addition of 4 lines of assembly to the UStrCat and UStrAsg functions, pushing the eax register onto the stack and popping it before exit. I haven’t reproduced the code here because the original is copyrighted to Embarcadero, but here are the changes required:
In UStrCat, Add push eax just after the conditional jump to UStrAsg, and pop eax just before the ret instruction.
In UStrAsg, wrap the call to FreeMem with a push eax and pop eax.
The patch function is also pretty straightforward:
procedure MonkeyPatch(OldProc, NewProc: PBYTE);
var
pBase, p: PBYTE;
oldProtect: Cardinal;
begin
p := OldProc;
pBase := p;
// Allow writes to this small bit of the code section
VirtualProtect(pBase, 5, PAGE_EXECUTE_WRITECOPY, oldProtect);
// First write the long jmp instruction.
p := pBase;
p^ := $E9; // long jmp opcode
Inc(p);
PDWord(p)^ := DWORD(NewProc) - DWORD(p) - 4; // address to jump to, relative to EIP
// Finally, protect that memory again now that we are finished with it
VirtualProtect(pBase, 5, oldProtect, oldProtect);
end;
function GetUStrCatAddr: Pointer; assembler;
asm
lea eax,System.@UStrCat
end;
initialization
MonkeyPatch(GetUStrCatAddr, @_UStrCatMonkey);
end.
This solution does give me the heebie jeebies, because we are patching the symptoms of the problem as we’ve seen them arise, without being able to either understand or address the root cause within the compiler. It’s not really possible to guarantee that there won’t be some other code path that causes this solution to come unstuck without really digging deep into the compiler’s code generation.
As noted, this problem appears to be resolved in Delphi XE5 or possibly earlier; however it is unclear if the root cause of the problem has been addressed, or we just got lucky. The issue has been reported as RSP-10255.
I was trying to debug a web application today, which is running in an Internet Explorer MSHTML window embedded in a thick client application. Weirdly, the app would fail, silently, without any script errors, on the sixth refresh — pressing F5 six times in a row would crash it each and every time. Ctrl+F5 or F5, either would do it.
I was going slightly mad trying to trace this, with no obvious solutions. Finally I loaded the process up in Windbg, not expecting much, and found that three (handled) C++ exceptions were thrown for each of the first 6 loads (initial load, + 5 refreshes):
(958.17ac): C++ EH exception - code e06d7363 (first chance)
(958.17ac): C++ EH exception - code e06d7363 (first chance)
(958.17ac): C++ EH exception - code e06d7363 (first chance)
However, on the sixth refresh, this exception was happening four times:
(958.17ac): C++ EH exception - code e06d7363 (first chance)
(958.17ac): C++ EH exception - code e06d7363 (first chance)
(958.17ac): C++ EH exception - code e06d7363 (first chance)
(958.17ac): C++ EH exception - code e06d7363 (first chance)
This gave me something to look at! At the very least there was an observable difference between the refreshes within the debugger. A little more spelunking revealed that the very last exception thrown was the relevant one, and it returned the following trace (snipped):
So now I knew that somewhere deep in my Javascript code there was something happening that was bad. Okay… I guess that helps, maybe?
But then, after some more googling, I discovered the following blog post, published a mere 9 days ago: Finally… JavaScript source line info in a dump. Magic! (In fact, I’m just writing this blog post for my future self, so I remember where to find this info in the future.)
After following the specific incantations outlined within that post, I was able to get the exact line of Javascript that was causing my weird error. All of a sudden, things made sense.
0:000> k
ChildEBP RetAddr
00186520 76bd22b4 KERNELBASE!RaiseException+0x48
00186558 5900775d msvcrt!_CxxThrowException+0x59
00186588 590076a3 jscript9!Js::JavascriptExceptionOperators::ThrowExceptionObjectInternal+0xb7
001865b8 5901503d jscript9!Js::JavascriptExceptionOperators::Throw+0x77
00186604 6365e79b jscript9!CJavascriptOperations::ThrowException+0x9c
0018662c 63e609aa mshtml!CFastDOM::ThrowDOMError+0x70
00186660 58f1f9a3 mshtml!CFastDOM::CWebSocket::DefaultEntryPoint+0xe2
001866c8 58f29994 jscript9!Js::JavascriptExternalFunction::ExternalFunctionThunk+0x165
00186724 58f2988c jscript9!Js::JavascriptFunction::CallAsConstructor+0xc7
00186744 58f29a4a jscript9!Js::InterpreterStackFrame::NewScObject_Helper+0x39
00186760 58f29a7a jscript9!Js::InterpreterStackFrame::ProfiledNewScObject_Helper+0x53
00186780 58f29aa9 jscript9!Js::InterpreterStackFrame::OP_NewScObject_Impl<Js::OpLayoutCallI_OneByte,1>+0x24
00186b58 58f26510 jscript9!Js::InterpreterStackFrame::Process+0x402b
00186d6c 14ea1ae1 jscript9!Js::InterpreterStackFrame::InterpreterThunk<1>+0x1e8
WARNING: Frame IP not in any known module. Following frames may be wrong.
00186d78 58faa407 js!Anonymous function [http://marcdev2010:4131/app/main/main-controller.js @ 251,7]
00186e70 15511455 jscript9!Js::JavascriptFunction::EntryApply+0x267
00186ed8 58f268e6 js!d [http://marcdev2010:4131/lib/angular/angular.min.js @ 34,479]
001872c8 58f26510 jscript9!Js::InterpreterStackFrame::Process+0x899
001873f4 14ea0681 jscript9!Js::InterpreterStackFrame::InterpreterThunk<1>+0x1e8
00187400 58f268e6 js!instantiate [http://marcdev2010:4131/lib/angular/angular.min.js @ 35,101]
001877e8 58f26510 jscript9!Js::InterpreterStackFrame::Process+0x899
00187944 14ea1b41 jscript9!Js::InterpreterStackFrame::InterpreterThunk<1>+0x1e8
00187950 58f268e6 js!Anonymous function [http://marcdev2010:4131/lib/angular/angular.min.js @ 67,280]
00187d38 58f26510 jscript9!Js::InterpreterStackFrame::Process+0x899
00187e74 14ea1c21 jscript9!Js::InterpreterStackFrame::InterpreterThunk<1>+0x1e8
...
When I looked at the line in question, line 251 of main-controller.js, I found:
// TODO: We need to handle the web socket connection going down -- it really should be wrappered
// try {
$scope.watcher = new WebSocket("ws://"+location.host+"/");
// } catch(e) {
// $scope.watcher = null;
// }
$scope.$on('$destroy', function() {
if($scope.watcher) {
$scope.watcher.close();
$scope.watcher = null;
}
});
It turns out that if I press F5, or call browser.navigate from the container app, the $destroy event was never called, and what’s worse, MSHTML wasn’t shutting down the web socket, either. And by default, Internet Explorer has a maximum of six concurrent WebSocket connections. So six page loads and we’re done. The connection error is not triggering a script error in the MSHTML host, sadly, which is why it was so hard to track down.
Yeah, if I had already written the error handling for the WebSocket connection in the JavaScript code, this issue wouldn’t have been so hard to trace. But at least I’ve learned a useful new debugging technique!
Speculation and further investigation:
I’m still working on why the web socket is staying open between page loads when embedded. It’s not straightforward, and while onbeforeunload is a workaround that, well, works, I hate workarounds when I don’t have a clear answer as to why they are needed.
It is possible that there is a circular reference leak or similar, but I did kinda think MS had sorted most of those with recent releases of IE.
This problem is only reproducible within the MSHTML embedded browser, and not within Internet Explorer itself. Changing $scope.watcher to window.watcher made no difference.
TWebBrowser (Delphi) and TEmbeddedWB (Delphi) both exhibited the same symptoms.
A far simpler document with a web socket call did not cause the problem.
Updated a few minutes later:
Yes, I have found the cause. It’s a classic Internet Explorer leak: a function within a closure that references the DOM. Simplified, it looks something like:
window.addEventListener( "load", function(event) {
var aa = document.getElementById('aa');
var watcher = new WebSocket("ws://"+location.host+"/");
watcher.onmessage = function() {
aa.innerHTML = 'message received';
}
aa.innerHTML = 'WebSocket started';
}, false);
This will persist the connection between page loads, and quickly eat up your available WebSocket connections. But it still only happens in the embedded web browser. Why that is, I am still exploring.
Updated 30 Nov 2015:
The reason this happens only in the embedded web browser is that by default, the embedded web browser runs in an emulation mode for IE7. Even with the X-UA-Compatible meta tag, you still need to add your executable to the FEATURE_BROWSER_EMULATION registry key.
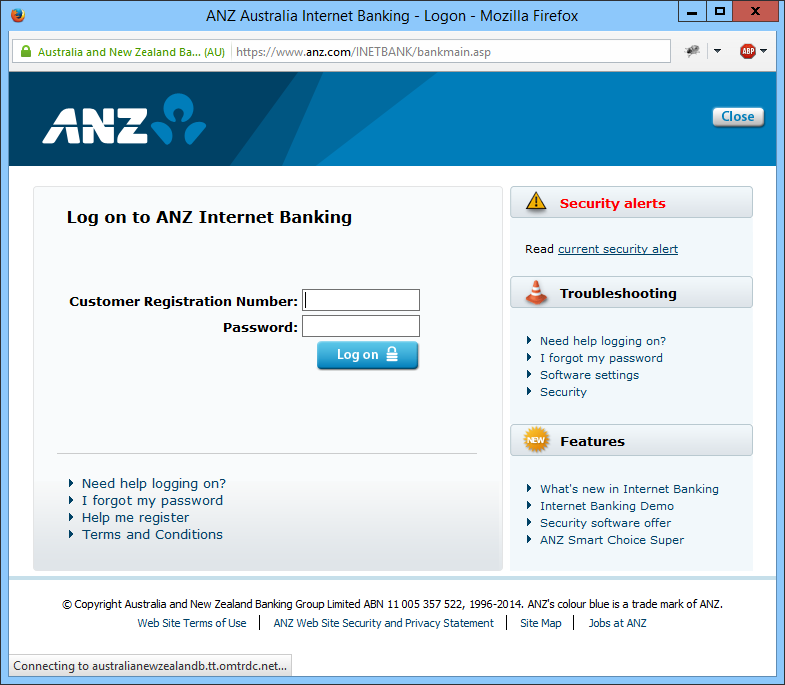
This morning, Firefox stalled while loading the login page for the ANZ Internet Banking website. Looking at the status bar, I could see that Firefox was attempting to connect to a website, australianewzealandb.tt.omtrdc.net. This raised immediate alarm bells, because I didn’t recognise the website address, and it certainly wasn’t an official anz.com sub-domain.
ANZ login delay – note the status message at the bottom of the window
The connection eventually started, and the page finished loading — just one of those little glitches loading web pages that everyone encounters all the time, right? But before I entered my ID and password, I decided I wasn’t comfortable to continue without knowing what that website was, and what resources it was providing to the ANZ site.
And here’s where things got a little scary.
It turns out that australianewzealandb.tt.omtrdc.net is a user tracking web site run by marketing firm Omniture, now a part of Adobe. The ANZ Internet Banking login page is requesting a Javascript script from the server, which currently returns the following tiny piece of code:
if (typeof(mboxFactories) !== 'undefined') {mboxFactories.get('default').get('SiteCatalyst: event', 0).setOffer(new mboxOfferDefault()).loaded();}
The Scare Factor
This script is run within the context of the Internet Banking login page. What can scripts that run within that context do? At worst, a script can be used to watch your login and password and send them (pretty silently) to a malicious host. This interaction may even be undetectable by the bank, and it would be up to you and your computer to be aware of this and block it — a big ask!
At worst, a script can be used to watch your login and password and send them to a malicious host.
The Relief
Now, this particular script is fortunately not malicious! In fact, as the mboxFactories variable actually is undefined on this page, this script does nothing at all. In other words, it’s useless and doesn’t even need to be there! (It’s defintely possible that the request for the script is being used on the server side to log client statistics, given the comprehensive parameters that are passed in the HTTPS request for the script.)
What are the risks?
So what’s the big deal with running third party script on a website?
The core issue is that scripts from third party sites can be changed at any time, without the knowledge of the ANZ Internet Banking team. In fact, different scripts can be served for different clients — a smart hacker would serve the original script for IP addresses owned by ANZ Bank, and serve a malicious script only to specific targeted clients. There would be no reliable way for the ANZ Internet Banking security team to detect this.
Scripts from third party sites can be changed at any time, without the knowledge of the Internet Banking team.
Another way of looking at this: it’s standard practice in software development to include code developed by other organisations in applications or websites. This is normal, sensible, and in fact unavoidable. The key here is that any code must be vetted and validated by a security team before deployment. If the bank hosts this code on their own servers, this is a straightforward part of the deployment process. When the bank instead references a third party site, this crucial security step is impossible.
Banking websites are among the most targeted sites online, for obvious reasons. I would expect their security policies to be conservative and robust. My research today surprised me.
Trust
How could third party scripts go wrong?
First, australianewzealandb.tt.omtrdc.net is not controlled by ANZ Bank. It’s controlled by a marketing organisation in another country. We don’t know how much emphasis they place on security. We are required to trust a third party from another country in order to login to our Internet Banking.
This means we need to trust that none of their employees are malicious, that they have strong procedures in place for managing updates to the site, the servers and infastructure, and that their organisation’s aims are coincident with the tight security requirements of Internet Banking. They need to have the same commitment to security that you would expect your bank to have. That’s a big ask for a marketing firm.
Security
The ANZ Internet Banking website is of course encrypted, served via HTTPS, the industry standard method of serving encrypted web pages.
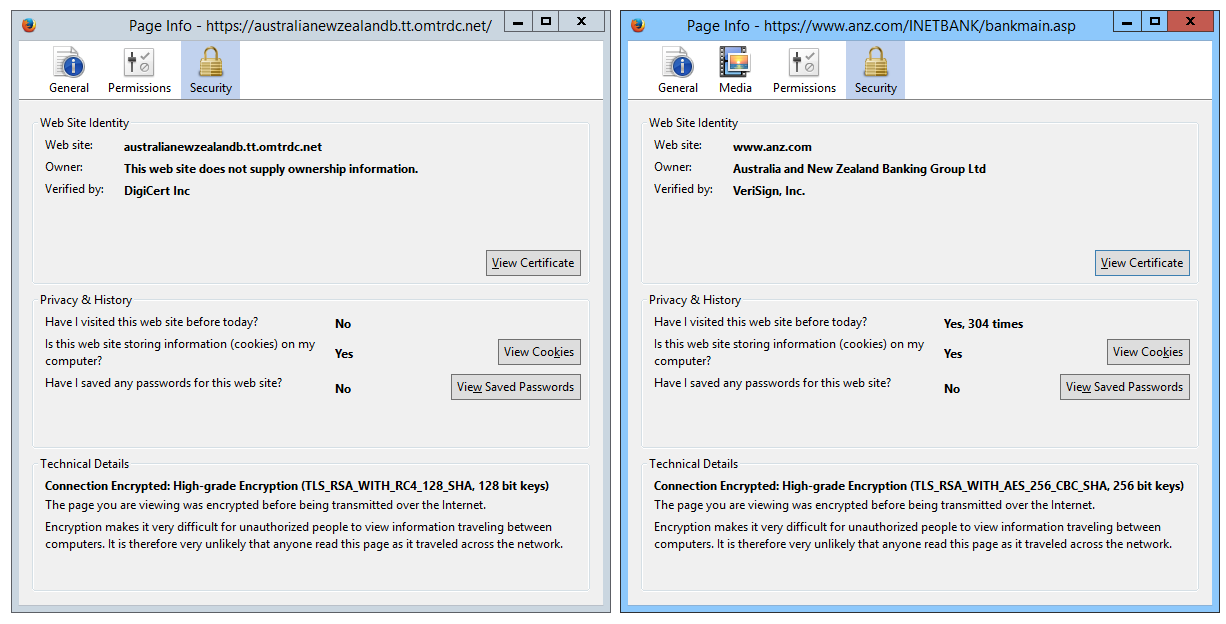
We can tell, just by looking at the address bar, that anz.com uses an Extended Validation certificate.
With a little simple detective work, we can also see that anz.com serves those pages using the TLS_RSA_WITH_AES_256_CBC_SHA encryption suite, using 256-bit keys. This is a good strong level of encryption, today.
However, australianewzealandb.tt.omtrdc.net does not measure up. In fact, this site uses 128-bit RC4+SHA encryption and integrity and does not have an Extended Validation certificate. RC4 is not a good choice today, and neither is SHA. This suggests immediately that security is not their top concern, which should then be an immediate concern to us!
ANZ vs Omtrdc Security
I should qualify this a little: Extended Validation certificates are not available for wildcard domains, which is the type of certificate that tt.omtrdc.net is using. This is for a good reason: “in order to ensure that EV SSL Certificates are not issued fraudulently or misused after issuance.” It’s worth thinking through that reason and seeing how it applies to this context.
Malicious Actors
So how could a nasty person steal your money?
In theory, if a nasty person managed to hack into the Adobe server, they could simply supply a script to the Internet Banking login page that captures your login details and sends them to a server, somewhere, anywhere, on the Internet. This means that we have to trust (there’s that word again) that the marketing firm will be proactive in updating and patching not only their Internet-facing servers, but their infrastructure behind those servers as well.
If a bad actor has compromised a certificate authority, as has happened severaltimesrecently, they can target these third party servers . Together with a DNS cache poisoning or Man-In-The-Middle (MITM) attack, even security-savvy users will be unlikely to notice fraudulent certificates on the script servers.
Security flaws like Heartbleed are exacerbated by this setup. Not only do the bank security team have to patch their own servers, they also have to push the third party vendors to patch theirs as a priority.
Protect Yourself
As a user, run security software. That’s an important first step. Security software is regularly refreshed with blacklists of known malicious sites, and this will hopefully minimize any window of opportunity that an untargeted attack may have. I’m not going to recommend any particular brand, because I pretty much hate them all.
If you want to unleash your inner geek and be aware of how sites are using third party script servers, you can use Developer Tools included in your browser — press F12 in Internet Explorer, Chrome or Firefox, and look for the Network tab to see a list of all resources referenced by the site. You may need to press Ctrl+F5 to trigger a ‘hard’ refresh before the list is fully populated.
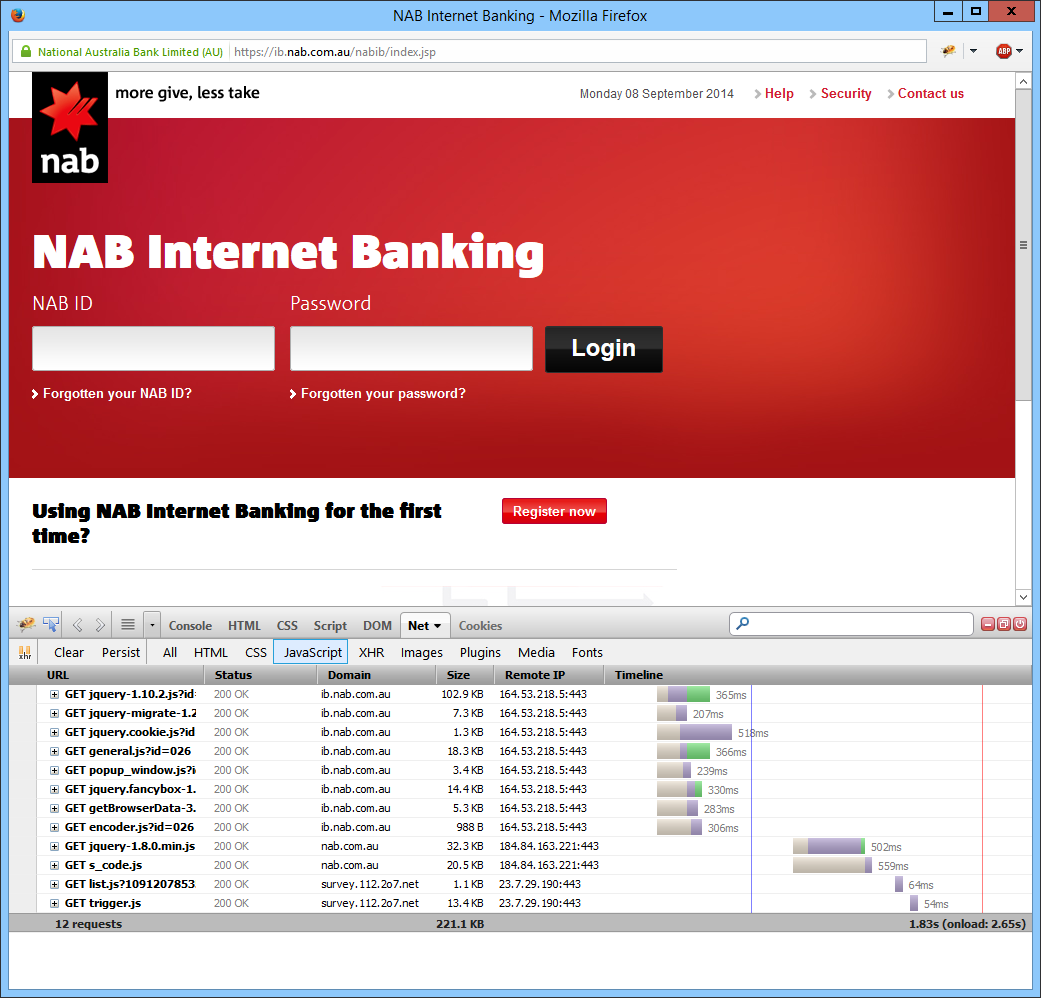
I’ve shown below the list of resources, filtered for Javascript, for the National Australia Bank Internet Banking site. You can see two scripts are loaded from one site — again, a market research firm.
Simplistic Advice for Banks
Specifically to mitigate this risk, banks should consider the following:
Serve all scripts from your own domain and vet any third party scripts that you serve before deployment.
In particular, check third party scripts for back end communication, via AJAX or other channels.
Minimize the number of third party scripts anywhere that secure content must be presented.
Use the Content-Security-Policy HTTP header to prevent third party scripts on supported browsers (most browsers today support this).
There are of course other mitigations, such as Two Factor Authentication (2FA), which do reduce risk. However, even 2FA should not be considered a silver bullet: it is certainly possible to modify the login page to take over your current login in real time — all the user would see is a message that they’d mistyped their password, and as they login again, the malicious hacker is actively draining money from their account.
A final thought on 2FA: do you really want a hacker to have your banking password, even if they don’t have access to your phone? Why do we have these passwords in the first place?
Browser Developers
I believe that browser vendors could mitigate the situation somewhat by warning users if secure sites reference third party sites for resources, in particular where these secure sites have lower quality protection than the first party site. This protection is already in place where content is requested over HTTP from a HTTPS site, known as mixed content warnings.
There is no value in an Extended Validation certificate if any of the resources requested by the site are served from a site with lower quality encryption! Similarly, if a bank believes that 256-bit AES encryption is needed for their banking website, a browser could easily warn the user that resources are being served with lower quality 128-bit RC4 encryption.
Australian Banks
After this little investigation, I took a quick look at the big four Australian banking sites — ANZ, Commonwealth Bank, National Australia Bank, and Westpac. Here’s what I found; this is a very high-level overview and contains only information provided by any web browser!
Bank
Bank site security
# 3rd party scripts
Third party sites
Third party security
ANZ Bank
256-bit AES (EV certificate)
1
australianewzealandb.tt.omtrdc.net
128-bit RC4
NAB
256-bit AES (EV certificate)
2
survey.112.2o7.net
256-bit AES
Westpac
128-bit AES (EV certificate)
None!
Commonwealth Bank
128-bit AES (EV certificate)
9!
ssl.google-analytics.com
128-bit AES
commonwealthbankofau.tt.omtrdc.net
128-bit RC4
google-analytics.com
128-bit AES
d1wscoizcbxzhp.cloudfront.net
128-bit AES
cba.demdex.net
128-bit AES
Do you see how the *.tt.omtrdc.net subdomains are used by two different banking sites? In fact, this domain is used by a large number of banking websites. That would make it an attractive target, wouldn’t you think?
I reached out to all 4 banks via Twitter (yeah, I know, I know, “reached out”, “Twitter”, I apologise already), and NAB was the first, and so far only, bank to respond:
@MarcDurdin Hi Marc, I'm keen to have our tech team look into this for you – could you pls DM me more details? ^TC
But I’m not here to talk about the record — I am more interested in the steps Windows XP users will take to mitigate the flaws, because Microsoft are not patching any of these vulnerabilities for Windows XP! Some people I’ve talked to, from individuals up to enterprises, seem to have the idea that they’ll practice “Safe Computing” and be able to continue using Windows XP and avoid paying for an upgrade.
What do I mean by Safe Computing? Y’know, don’t open strange attachments, use an alternate web browser, view emails with images switched off, keep antivirus and malware protection software up to date, remove unused applications, disable unwanted features, firewalls, mail and web proxies, so on and so forth.
So let’s look at what the repercussions are of practicing Safe Computing in light of these disclosures.
The first mitigation you are going to take is, obviously, to stop using Internet Explorer. With this many holes, you are clearly not going to be able to use Internet Explorer at all. This means a loss of functionality, though: those Internet Explorer-optimised sites (I’m looking at you, just about every corporate intranet) often don’t even work with non-IE browsers. So if you have to use IE to view these ‘trusted’ sites, you must ensure you never click on an external link, or you will be exposed again. Doable, but certainly a hassle.
Okay, so you don’t use IE now. You use Firefox, or Chrome. But you’re still in trouble, because it turns out that the very next security bulletin announces that GDI+ and Uniscribe are both vulnerable as well, today. GDI+ is used to display images and render graphics in Windows, and Uniscribe is used by just about every application to draw text onto the screen, including all the major web browsers. The Uniscribe flaw relates to how it processes fonts. The GDI+ flaw relates to a specific metafile image format.
So, disable support for downloadable fonts in your browser, and disable those specific metafile image types in the Windows Registry. Yes, it can be done. Now you’ll be all good, right? You don’t need those fonts, or those rare image types, do you? You can still surf the web okay?
But you’ve lost functionality, which we might not value all that highly, but it’s still a trade-off you’ve had to make.
From today, every security flaw that is announced will force you to trade more functionality for security.
And this is my point. From today, and on into the future, every security flaw that is announced will force you to trade yet more functionality for security. Eventually, you will only be able to use Windows XP offline — it simply will not be possible to safely access Internet resources without your computer and your data being compromised. It’s going to get worse from here, folks. It is well and truly past time to upgrade.
I tell a lie. Only 21 of those 59 vulnerabilities impact IE8 on Windows XP. You're all good, forget I said anything. http://t.co/1fmrbIB6mU
One of the most irritating server configuration issues I’ve run across recently emerged when adding global MIME type mappings to Microsoft Internet Information Services 7 — part of Windows Server 2008 R2.
Basically, if you have a MIME type mapping in a domain or path, and later add a mapping for the same file extension at a higher level in the configuration hierarchy, any subsequent requests to that domain or path will start returning HTTP 500 server errors.
You will not see any indication of conflicts, when you change the higher level MIME type mappings, and you typically only discover the error when a user complains that a specific page or site is down.
When you check your logs, you’ll see an error similar to the following:
\\?\C:\Websites\xxx\www\web.config ( 58) :Cannot add duplicate collection
entry of type 'mimeMap' with unique key attribute
'fileExtension' set to '.woff'
Furthermore, if you try and view the MIME types in the path or domain that is faulting within IIS Manager, you will receive the same error and will not be able to either view or address the problem (e.g. by removing the MIME type at that level, which would be the logical way to address the problem). The only way to address the problem in the UI view is to remove the global MIME mapping that is conflicting — or manually edit the web.config file at the lower level.
Not very nice — especially on shared hosts where you may not control the global settings!
As per severalQCreports, Data.DBXJSON.TJSONString.ToString is still very broken. Which means, for all intents and purposes, TJSONAnything.ToString is also broken. Fortunately, you can just use TJSONAnything.ToBytes for a happy JSON outcome.
The following function will take any Delphi JSON object and convert it to a string:
function JSONToString(obj: TJSONAncestor): string;
var
bytes: TBytes;
len: Integer;
begin
SetLength(bytes, obj.EstimatedByteSize);
len := obj.ToBytes(bytes, 0);
Result := TEncoding.ANSI.GetString(bytes, 0, len);
end;
Because TJSONString.ToBytes escapes all characters outside U+0020-U+007F, we can assume that the end result is 7-bit clean, so we can use TEncoding.ANSI. You could instead stream the TBytes to a file or do other groovy things with it.
Today I’ve got a process on my machine that is supposed to be exiting, but it has hung. Let’s load it up in Windbg and find what’s up. The program in question was built in Delphi XE2, and symbols were generated by our internal tds2dbg tool (but there are other tools online which create similar .dbg files). As usual, I am writing this up for my own benefit as much as anyone else’s, but if I put it on my blog, it forces me to put in enough detail that even I can understand it when I come back to it!
Looking at the main thread, we can see unit finalizations are currently being called, but the specific unit finalization section and functions which are being called are not immediately visible in the call stack, between InterlockedCompareExchange and FinalizeUnits:
So, the simplest way to find out where we were was to step out of the InterlockedCompareExchange call. I found myself in System.SysUtils.DoneMonitorSupport (specifically, the CleanEventList subprocedure):
0:000> p
eax=01a8ee70 ebx=01a8ee70 ecx=01a8ee70 edx=00000001 esi=00000020 edi=01a26e80
eip=0042dcb1 esp=0018ff20 ebp=0018ff3c iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00200202
audit4_patient!CleanEventList+0xd:
0042dcb1 33c9 xor ecx,ecx
After a little more spelunking, and a review of the Delphi source around this function, I found that this was a part of the System.TMonitor support. Specifically, there was a locked TMonitor somewhere that had not been destroyed. I stepped through a loop that was spinning, waiting for the object to be unlocked so its handle could be destroyed, and found a reference to the data in question here:
0:000> p
eax=00000001 ebx=01a8ee70 ecx=01a8ee70 edx=00000001 esi=00000020 edi=01a26e80
eip=0042dcaf esp=0018ff20 ebp=0018ff3c iopl=0 nv up ei pl nz na po nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00200202
audit4_patient!CleanEventList+0xb:
0042dcaf 8bc3 mov eax,ebx
Looking at the record pointed to by ebx, we had a reference to an event handle handy:
Although Event is a Pointer, internally it’s just cast from an event handle. So I guess that we can probably find another reference to that handle somewhere in memory, corresponding to a TMonitor record:
Now one of these should correspond to a TMonitor record. The first entry (01a8ee74) is just part of our TSyncEventItem record, and the next three don’t make sense given that the FSpinCount (the next value in the memory dump) would be invalid. So let’s look at the last one. Counting quickly on all my fingers and toes, I establish that that makes 08a47538 the start of the TMonitor record. And… so we search for a pointer to that.
Just one! But here it gets a little tricky, because the PMonitor pointer is in a ‘hidden’ field at the end of the object. So we need to locate the start of the object.
I’m just stabbing in the dark here, but that 004015c8 that’s just four bytes back smells suspiciously like an object class pointer. Let’s see:
0:000> da poi(4015c8-38)+1
004016d7 "TObject&"
Ta da! That all fits. A TObject has no data members, so the next 4 bytes should be the TMonitor (search for hfMonitorOffset in the Delphi source to learn more). So we have a TObject being used as a TMonitor lock reference. (Learn about that poi(address-38)+1 magic). But what other naughty object is hanging about, using this TObject as its lock?
TThreadList = class
private
FList: TList;
FLock: TObject;
FDuplicates: TDuplicates;
Yes, that definitely looks hopeful! That FLock is pointing to our lock TObject… I believe that’s called a Quality Match.
This is still a little bit too generic for me, though. TThreadList is a standard Delphi class used by the bucketload. Let’s try and identify who is using this list and leaving it lying about. First, we’ll quickly have a look at that TThreadList.FList to see if it has anything of interest — that’s the first data member in the object == object+4.
Yep, it’s a TList. Just making sure. It’s empty, what a shame (TList.FCount is the second data member in the object == 00000000, as is the list pointer itself).
So how else can we find the usage of that TThreadList? Is it TThreadList referenced anywhere then? Break out the search tool again!
0:000> !handle 91c
Could not duplicate handle 91c, error 6
That suggests that the object has already been destroyed. But that the TThreadList hasn’t.
And sure enough, when I looked at the destructor for TAnatomyDiagramTileLoadThread, we clear the TThreadList, but we never free it!
Now, another way we could have caught this was to turn on leak detection. But leak detection is not always perfect, especially when you get some libraries that *cough* have a lot of false positives. And of course while we could have switched on heap leak detection, that involves rebuilding and restarting the process and losing the context along the way, with no guarantee we’ll be able to reproduce it again!
While this approach does feel a little tedious, and we did have some luck in this instance with freed objects not being overwritten, and the values we were searching for being relatively unique, it does nevertheless feel pretty deterministic, which must be better than the old “try-it-and-hope” debugging technique.


 Security flaws like
Security flaws like