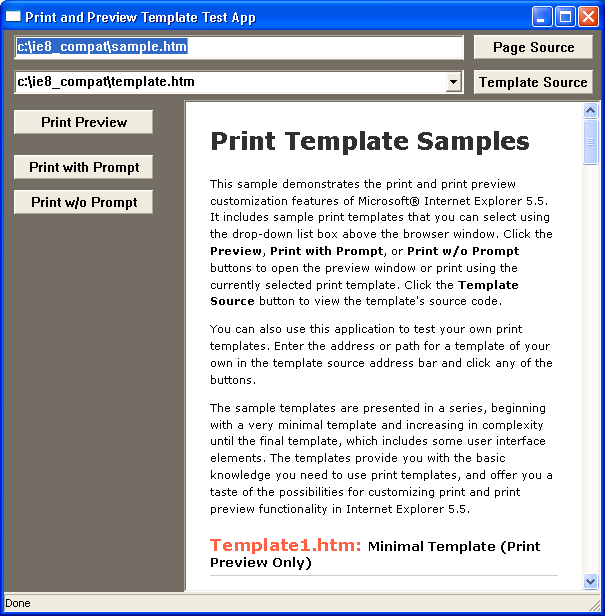
I’m writing up these notes in order to document what has been a long and painful process, involving much spelunking through MSHTML.DLL and IEFRAME.DLL to try and understand what Internet Explorer (or more accurately, the WebBrowser control) is doing and how to correctly use the semi-documented interfaces to provide full control over a print job.
The original requirement for this mini-project was to provide tray, collation, and duplex control for a HTML print job using IHTMLDocument2.execCommand(IDM_PRINT), with a custom print template. These functions had been supported through a 3rd party ActiveX component, but this component proved to be incompatible with Internet Explorer 9 (causing a blue screen would you believe!), and the company providing the component was defunct, so it fell to me to re-engineer the solution.
After considerable research, I found some sparse documentation on MSDN suggesting that one could pass a HTMLDLG_PRINT_TEMPLATE flag to ShowHTMLDialogExand thereby duplicate and extend the functionality of the print template. In particular, the __IE_CMD_Printer_Devmode property that could somehow be passed into this function would give us the ability to control anything we liked in terms of the printer settings.
Too easy. Much too easy. The first stumbling block was trying to discover the type of the pvarArgIn parameter to ShowHTMLDialogEx. A variant array seemed sensible but did not work. It turns out that this needs to be an IHTMLEventObj, which can be created with IHTMLDocument4.CreateEventObject. You can then use IHTMLEventObj2.setAttribute to set the various attributes for the object.
Then there were questions about what IMoniker magic was needed for the pMk parameter. And more questions about the most appropriate set of flags. Diving into the debugger to examine what Microsoft did answered both of these questions — it was a simple CreateURLMonikerEx call, no need to bind the moniker or other magic, and the flags that Microsoft used were HTMLDLG_ALLOW_UNKNOWN_THREAD or HTMLDLG_NOUI or HTMLDLG_MODELESS or HTMLDLG_PRINT_TEMPLATE for a print job, or HTMLDLG_ALLOW_UNKNOWN_THREAD or HTMLDLG_MODAL or HTMLDLG_MODELESS or HTMLDLG_PRINT_TEMPLATE for a print preview job. Yes, that is both HTMLDLG_MODAL and HTMLDLG_MODELESS!
Next, what variant type should the __IE_BrowseDocument attribute be? VT_DISPATCH or VT_UNKNOWN? The answer is VT_UNKNOWN — things just won’t work if you pass a VT_DISPATCH. I also came unstuck on the __IE_PrinterCmd_DevMode and __IE_PrinterCmd_DevNames attributes. These need to be a VT_I4 containing an unlocked HGLOBAL that references a DEVMODEW structure. I’ll leave the setup of the DEVMODEW structure to you: there are a lot of examples of that online.
However, even after overcoming these hurdles (with copious debugging to understand what MSHTML.DLL and IEFRAME.DLL were doing), there were other issues. First, the print template was unable to access the dialogArguments.__IE_BrowseDocument property, with an Access Denied error thrown. Also, HTC behaviors would fail to load as the WebBrowser component believed that they were being referenced in an insecure, cross-domain manner. And finally, JavaScript in the page being printed was failing to run — and this JavaScript was required to render some of the details of the page.
I knew that Microsoft actually pass a reference to a temporary file for printing in the __IE_ContentDocumentURL attribute. So I saved the file to a temporary file, which also required adding a BASE element to the header so that relative URLs in the document would resolve. But the problems had not gone away.
All three of these problems in reality stemmed from the same root cause. The security IDs for the various elements — the print template, the document being printed, and the HTC components — were not matching. So I embarked on an attempt to find out why. At first I wondered if we needed to bind the moniker to a bind context or storage. That was a no-go. Then I looked at the IInternetSecurityManager interface, which a developer can implement to provide custom security IDs, zones and more. Sounds logical, right? Only problem is that the ShowHTMLDialogEx function provides its own IInternetSecurityManager implementation, which you cannot override (and its GetSecurityID just returns INET_E_DEFAULTACTION for the relevant URLs). Yikes.
I was starting to run out of options. As far as I could tell, we were duplicating Microsoft’s functionality essentially identically, and I could not see any calls which changed the security for the document so that it would match security contexts.
Finally I noticed an undocumented attribute had been added to the HTML element in the temporary copy of the page: __IE_DisplayURL. And as soon as I added that to my file, referencing the original URL of the document, everything worked!
Now, this is all fun (and sounds straightforward in hindsight), but without some code it’s probably not terribly helpful. So here’s some code (in Delphi, translate to your favourite language as required). It all looks pretty straightforward now(!), but nearly every line involved blood, sweat and tears! This is really not a complete example and hence does not compile but just covers the bits necessary to complement the better documented aspects of custom printing with MSHTML. Please note that this example uses the TEmbeddedWB component for Delphi, and that temporary file cleanup has been excluded.
procedure THTMLPrintController.StartPrint(FPrint: Boolean);
var
FDeviceW, FDriverW, FPortW: WideString;
FDevModeHandle, FDevNamesHandle: HGLOBAL;
pEventObj2: IHTMLEventObj2;
procedure SetTempFileName;
begin
FTempFileName := GetTempFileName('', '.htm');
end;
{ SaveToFile: Saves the current web document to a temporary file, adding the required BASE and HTML properties }
procedure SaveToFile;
var
FElementCollection: IHTMLElementCollection;
FHTMLElement: IHTMLElement;
FBaseElement: IHTMLBaseElement;
FString: WideString;
begin
FElementCollection := webBrowser.Doc3.getElementsByTagName('base');
if FElementCollection.length = 0 then
begin
FBaseElement := webBrowser.Doc2.createElement('base') as IHTMLBaseElement;
FBaseElement.href := webBrowser.LocationURL;
(webBrowser.Doc3.getElementsByTagName('head').item(0,0) as IHTMLElement2).insertAdjacentElement('afterBegin', FBaseElement as IHTMLElement);
end
else
begin
FBaseElement := FElementCollection.item(0,0) as IHTMLBaseElement;
if FBaseElement.href = '' then FBaseElement.href := webBrowser.LocationURL;
end;
FElementCollection := webBrowser.Doc3.getElementsByTagName('html');
if FElementCollection.length > 0 then
begin
FHTMLElement := FElementCollection.item(0,0) as IHTMLElement;
FHTMLElement.setAttribute( '__IE_DisplayURL', webBrowser.LocationURL, 0);
end;
with TFileStream.Create(FTempFileName, fmCreate) do
try
if webBrowser.Doc5.compatMode = 'CSS1Compat' then
begin
FString := '';
Write(PWideChar(FString)^, Length(FString)*2);
end;
FString := webBrowser.Doc3.documentElement.outerHTML;
Write(PWideChar(FString)^, Length(FString)*2);
finally
Free;
end;
end;
{ Configured the printer, assuming we've already been passed an ANSI handle }
procedure ConfigurePrinter;
var
FDevice, FDriver, FPort: array[0..255] of char;
FDevModeHandle_Ansi: HGLOBAL;
FPrinterHandle: THandle;
FDevMode: PDeviceModeW;
FDevNames: PDevNames;
FSucceeded: Boolean;
sz: Integer;
Offset: PChar;
begin
Printer.GetPrinter(FDevice, FDriver, FPort, FDevModeHandle_Ansi);
if FDevModeHandle_Ansi = 0 then
RaiseLastOSError;
FDeviceW := FDevice;
FDriverW := FDriver;
FPortW := FPort;
{ Setup the DEVMODE structure }
FSucceeded := False;
if not OpenPrinterW(PWideChar(FDeviceW), FPrinterHandle, nil) then
RaiseLastOSError;
try
sz := DocumentPropertiesW(0, FPrinterHandle, PWideChar(FDeviceW), nil, nil, 0);
if sz < 0 then RaiseLastOSError;
FDevModeHandle := GlobalAlloc(GHND, sz);
if FDevModeHandle = 0 then RaiseLastOSError;
try
FDevMode := GlobalLock(FDevModeHandle);
if FDevMode = nil then
RaiseLastOSError;
try
if DocumentPropertiesW(0, FPrinterHandle, PWidechar(FDeviceW), FDevMode, nil, DM_OUT_BUFFER) < 0 then
RaiseLastOSError;
FDevMode.dmFields := FDevMode.dmFields or DM_DEFAULTSOURCE or DM_DUPLEX or DM_COLLATE;
FDevMode.dmDefaultSource := FTrayNumber;
if FDuplex
then FDevMode.dmDuplex := DMDUP_VERTICAL
else FDevMode.dmDuplex := DMDUP_SIMPLEX;
if FCollate
then FDevMode.dmCollate := DMCOLLATE_TRUE
else FDevMode.dmCollate := DMCOLLATE_FALSE;
if DocumentPropertiesW(0, FPrinterHandle, PWideChar(FDeviceW), FDevMode, FDevMode, DM_OUT_BUFFER or DM_IN_BUFFER) < 0 then
RaiseLastOSError;
FSucceeded := True;
finally
GlobalUnlock(FDevModeHandle);
end;
finally
if not FSucceeded then GlobalFree(FDevModeHandle);
end;
finally
ClosePrinter(FPrinterHandle);
end;
Assert(FSucceeded);
{ Setup up the DEVNAMES structure }
FSucceeded := False;
FDevNamesHandle := GlobalAlloc(GHND, SizeOf(TDevNames) +
(Length(FDeviceW) + Length(FDriverW) + Length(FPortW) + 3) * 2);
if FDevNamesHandle = 0 then RaiseLastOSError;
try
FDevNames := PDevNames(GlobalLock(FDevNamesHandle));
if FDevNames = nil then RaiseLastOSError;
try
Offset := PChar(FDevNames) + SizeOf(TDevnames);
with FDevNames^ do
begin
wDriverOffset := (Longint(Offset) - Longint(FDevNames)) div 2;
Move(PWideChar(FDriverW)^, Offset^, Length(FDriverW) * 2 + 2);
Inc(Offset, Length(FDriverW) * 2 + 2);
wDeviceOffset := (Longint(Offset) - Longint(FDevNames)) div 2;
Move(PWideChar(FDeviceW)^, Offset^, Length(FDeviceW) * 2 + 2);
Inc(Offset, Length(FDeviceW) * 2 + 2);
wOutputOffset := (Longint(Offset) - Longint(FDevNames)) div 2;
Move(PWideChar(FPortW)^, Offset^, Length(FPortW) * 2 + 2);
end;
FSucceeded := True;
finally
GlobalUnlock(FDevNamesHandle);
end;
finally
if not FSucceeded then GlobalFree(FDevNamesHandle);
end;
Assert(FSucceeded);
end;
{ Creates the IHTMLEventObj2 and populates the attributes for printing }
procedure CreateEventObject;
var
v: OleVariant;
FShortFileName: WideString;
FShortFileNameBuf: array[0..260] of widechar;
begin
v := EmptyParam;
pEventObj2 := webBrowser.Doc4.CreateEventObject(v) as IHTMLEventObj2;
pEventObj2.setAttribute('__IE_BaseLineScale', 2, 0);
GetShortPathNameW(PWideChar(FTempFileName), FShortFileNameBuf, 260); FShortFileName := FShortFileNameBuf;
v := webBrowser.Document as IUnknown;
pEventObj2.setAttribute('__IE_BrowseDocument', v, 0);
pEventObj2.setAttribute('__IE_ContentDocumentUrl', FShortFileName, 0);
pEventObj2.setAttribute('__IE_ContentSelectionUrl', '', 0); // Empty as we never print selections
pEventObj2.setAttribute('__IE_FooterString', '', 0);
pEventObj2.setAttribute('__IE_HeaderString', '', 0);
pEventObj2.setAttribute('__IE_ActiveFrame', 0, 0);
pEventObj2.setAttribute('__IE_OutlookHeader', '', 0);
pEventObj2.setAttribute('__IE_PrinterCMD_Device', FDeviceW, 0);
pEventObj2.setAttribute('__IE_PrinterCMD_Port', FPortW, 0);
pEventObj2.setAttribute('__IE_PrinterCMD_Printer', FDriverW, 0);
pEventObj2.setAttribute('__IE_PrinterCmd_DevMode', FDevModeHandle, 0);
pEventObj2.setAttribute('__IE_PrinterCmd_DevNames', FDevNamesHandle, 0);
if FPrint
then pEventObj2.setAttribute('__IE_PrintType', 'NoPrompt', 0)
else pEventObj2.setAttribute('__IE_PrintType', 'Preview', 0);
pEventObj2.setAttribute('__IE_TemplateUrl', GetPrintTemplateURL, 0);
pEventObj2.setAttribute('__IE_uPrintFlags', 0, 0);
v := VarArrayOf([FShortFileName]);
pEventObj2.setAttribute('__IE_TemporaryFiles', v, 0);
pEventObj2.setAttribute('__IE_ParentHWND', 0, 0);
pEventObj2.setAttribute('__IE_HeaderString', webBrowser.Doc2.title, 0);
pEventObj2.setAttribute('__IE_DisplayURL', webBrowser.LocationURL, 0);
end;
procedure InstantiateDialog;
var
FWindowParams, FMonikerURL: WideString;
FMoniker: IMoniker;
FDialogFlags: DWord;
varArgIn, varArgOut: OleVariant;
res: HRESULT;
begin
varArgIn := pEventObj2 as IUnknown;
varArgOut := Null;
FMonikerURL := GetPrintTemplateURL;
OleCheck(CreateURLMonikerEx(nil, PWideChar(FMonikerURL), FMoniker, URL_MK_UNIFORM));
if FPrint then
begin
FWindowParams := '';
FDialogFlags := HTMLDLG_ALLOW_UNKNOWN_THREAD or HTMLDLG_NOUI or HTMLDLG_MODELESS or HTMLDLG_PRINT_TEMPLATE;
end
else
begin
FWindowParams := 'resizable=yes;';
FDialogFlags := HTMLDLG_ALLOW_UNKNOWN_THREAD or HTMLDLG_MODAL or HTMLDLG_MODELESS or HTMLDLG_PRINT_TEMPLATE;
end;
res := ShowHTMLDialogEx(0, FMoniker, FDialogFlags, varArgIn, PWideChar(FWindowParams), varArgOut);
if res <> S_OK then raise EOSError.Create(SysErrorMessage(res));
end;
begin
SetTempFileName;
SaveToFile;
ConfigurePrinter;
CreateEventObject;
InstantiateDialog;
end;
Update 14 July: This code is not our production code: I’ve stripped out bits and pieces and tried to keep the bits that are somewhat relevant. Don’t worry too much about the ConfigurePrinter details — the takeaway is the HGLOBAL. I must also apologise for the atrocity that is the SaveToFile function. That’s what you get when working with legacy versions of software. Internet Explorer also won’t reliably work with non-ASCII content there unless you toss a BOM into the start of the stream.