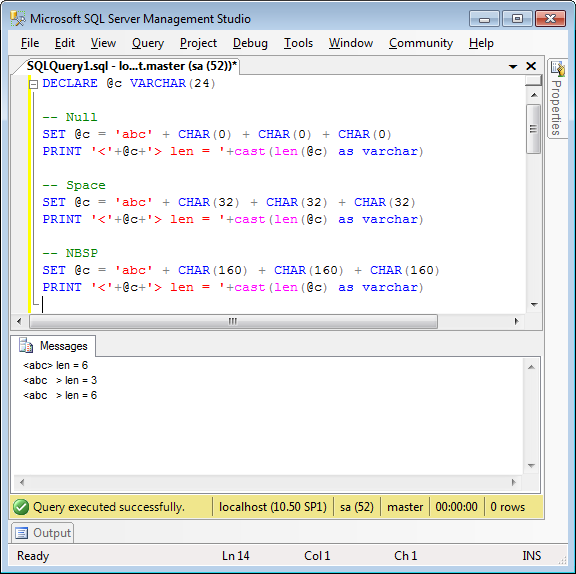
I was preparing a new git repository today for a website, on my Windows machine, and moving a bunch of existing files over for addition. When I ran git add ., I ran into a weird error:
C:\tavultesoft\website\help.keyman.com> git add . fatal: unable to stat 'desktop/docs/desktop_images/usage-none.PNG': No such file or directory
How could a file be there — and not there? I fired up Explorer to find the file and there it was, looked fine. I’d just copied there, so of course it was there!
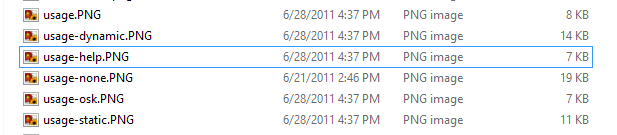
For a moment, I scratched my head, trying to figure out what could be wrong. The file looked fine. It was in alphabetical order, so it seemed that the letters were of the correct script.
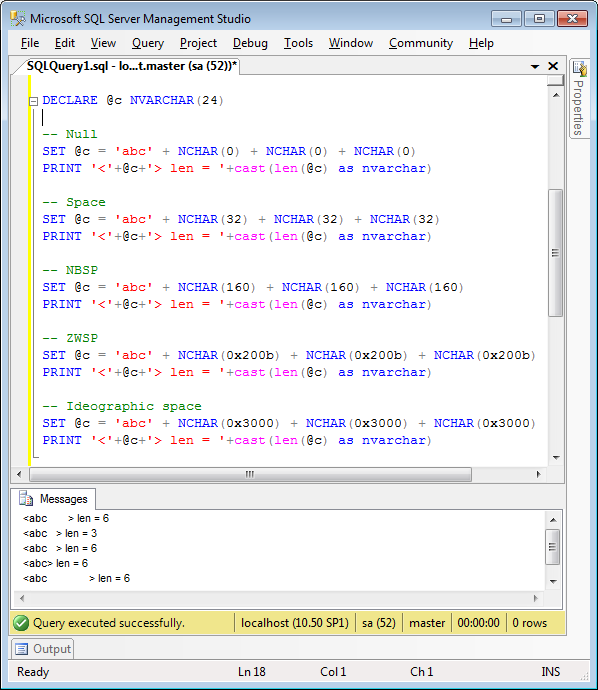
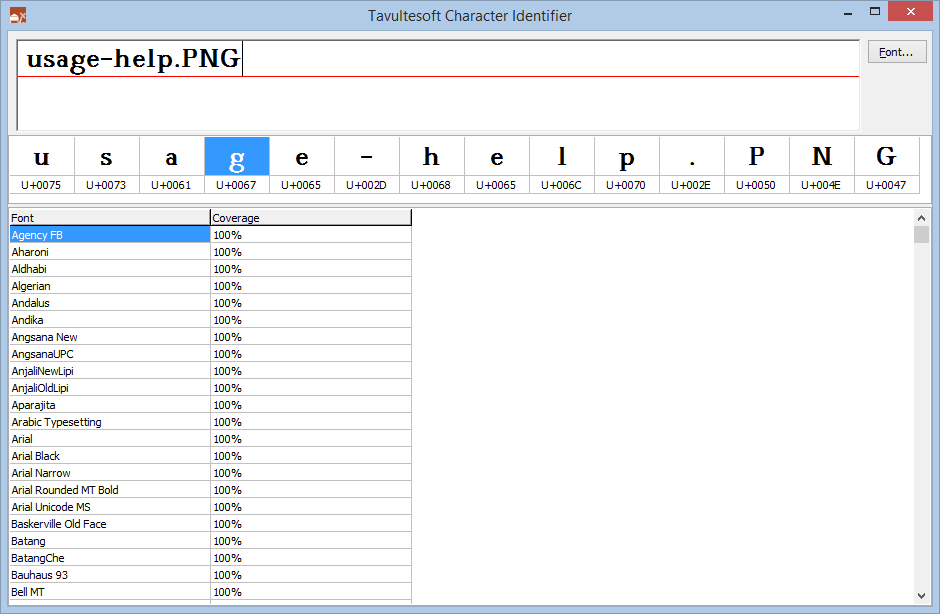
Being merely a bear of little brain, it took me some time to realise that I could just examine the character codepoints in the filename. When this finally sunk in, I quickly pulled out my handy charident tool and copied the filename text to the clipboard:

And pasted it into the Character Identifier:
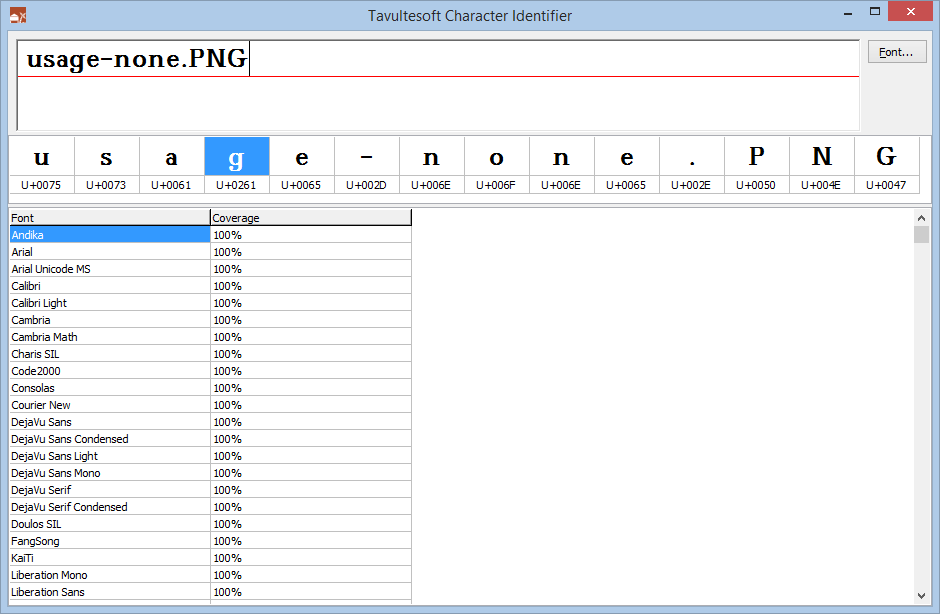
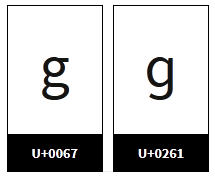
With a quick scan of the Unicode code points, I quickly noticed that, sure enough, the letter ‘g‘ (highlighted) was not what was expected. It turns out that U+0261 is LATIN SMALL LETTER SCRIPT G, not quite what was anticipated (U+0067 LATIN SMALL LETTER G). And in the Windows 8.1 fonts used in Explorer, the ‘ɡ‘ and ‘g‘ characters look identical!
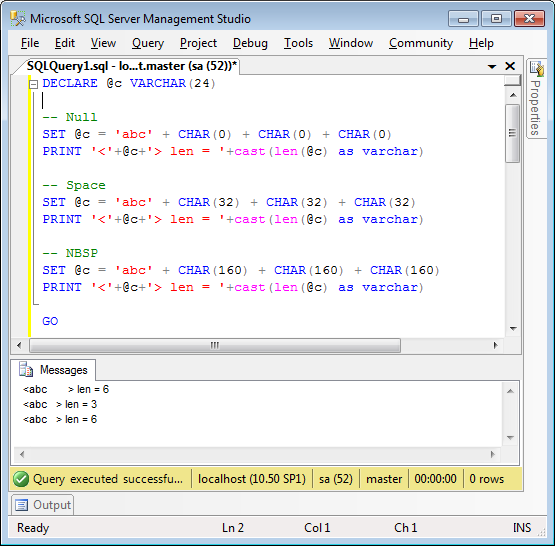
I checked some of the surrounding files as well. And looking at usage-help.PNG, I could see no problems with it:
So why did git get so confused? OK, so git is a tool ported from the another world (“Linux”). It doesn’t quite grok Windows character set conventions for filenames. This is kinda what it saw when looking at the file (yes, that’s from a dir command):
![]()
But then somewhere in the process, a normalisation was done on the original filename, converting ɡ to g, and thus it found a mismatch, and reported a missing usage-none.PNG.
Windows does a similar compatibility normalisation and so confuses the user with seemingly sensible sort orders. But it doesn’t prevent you from creating two files with visually identical names, thus:

I’m sure there’s a security issue there somewhere…