This is a really quick post, just noting more flexible ways of handling exceptions in WinDBG, for example ignoring EIdConnClosedGracefully or EAbort by default.
There are two parts to this:
Use script files to build complex breakpoint or exception statements. While you could technically embed it all in one line, it becomes increasingly unwieldy. It’s still painful in a script file but slightly less so.
Use as to create aliases for specific memory addresses in the script, making string comparisons much simpler.
To tell WinDbg to use a script file when a Delphi exception occurs:
$$
$$ Report on Delphi exceptions: setup aliases
$$
.block {
as ${/v:exception_cleanup} ad /q ${/v:exception_message}; ad /q ${/v:exception_name}; ad /q ${/v:exception_address}
}
.block {
exception_cleanup
}
.block {
aS /mu ${/v:exception_message} poi(poi(ebp+1c)+4)
aS /ma ${/v:exception_name} poi(poi(poi(ebp+1c))-38)+1
aS /x ${/v:exception_address} poi(ebp+4)
}
$$
$$ Do everything in this block, no matter what the exception is. This way we
$$ get reports on exceptions without interrupting program execution. You may want to
$$ add extra reporting, e.g. stack traces, other variables.
$$
.block {
.echo Delphi exception exception_name at ${exception_address}: exception_message
}
$$
$$ In this block, we add conditionals for exception types we want to ignore, or even
$$ specific addresses or other conditions as you need.
$$
$$ Don't include anything below this block, not even comments, because that breaks the
$$ "gc" command
$$
.block {
.if ($scmp( "${exception_name}", "EIdConnClosedGracefully") == 0) { exception_cleanup; gc }
.elsif ($scmp( "${exception_name}", "EAbort") == 0) { exception_cleanup; gc }
.else {
.echo
exception_cleanup
}
}
Yes, this file has a bit of complexity in it. The WinDbg script interpreter is excessively pernickity. Important things to note are:
aliases are not expanded until the block is started (hence usage of the aliases is in a separate block to the definition)
you can’t have any additional statements after a block containing a gc or t or similar command, otherwise the script interpreter has a little hissy fit
the exception_cleanup alias is pretty essential to avoid leaving aliases about that then get expanded at the wrong time (leading to premature expansion of aliases from a previous exception).
the exception_name alias is not 100% reliable. This is because it is referencing a Delphi short string, which is not null-terminated, leading to garbage characters displayed at the end in some cases. Sadface. There is probably a way to work around this but I haven’t found it yet.
You’ll see sometimes I use the ${alias_name} expansion and other times I use just alias_name. Use ${alias_name} where non-whitespace characters may be immediately after the alias, as they will be interpreted as part of the alias.
The ${/v:alias_name} version prevents expansion of the alias, which is useful for referring to the name of the alias if it is already defined, for example to delete it.
Useful knowledge on WinDbg scripts from other sources:
This is a list of my blog posts on using WinDBG with Delphi apps, mostly for my reference. Internally, I use a version of tds2dbg with some private modifications, but you should have reasonable results with the public version.
While other Khmer keyboards exist for iOS and Android, I wanted to try playing with one myself, given I am currently learning Khmer. Creating a keyboard layout is a great way to rapidly become very familiar with a script!
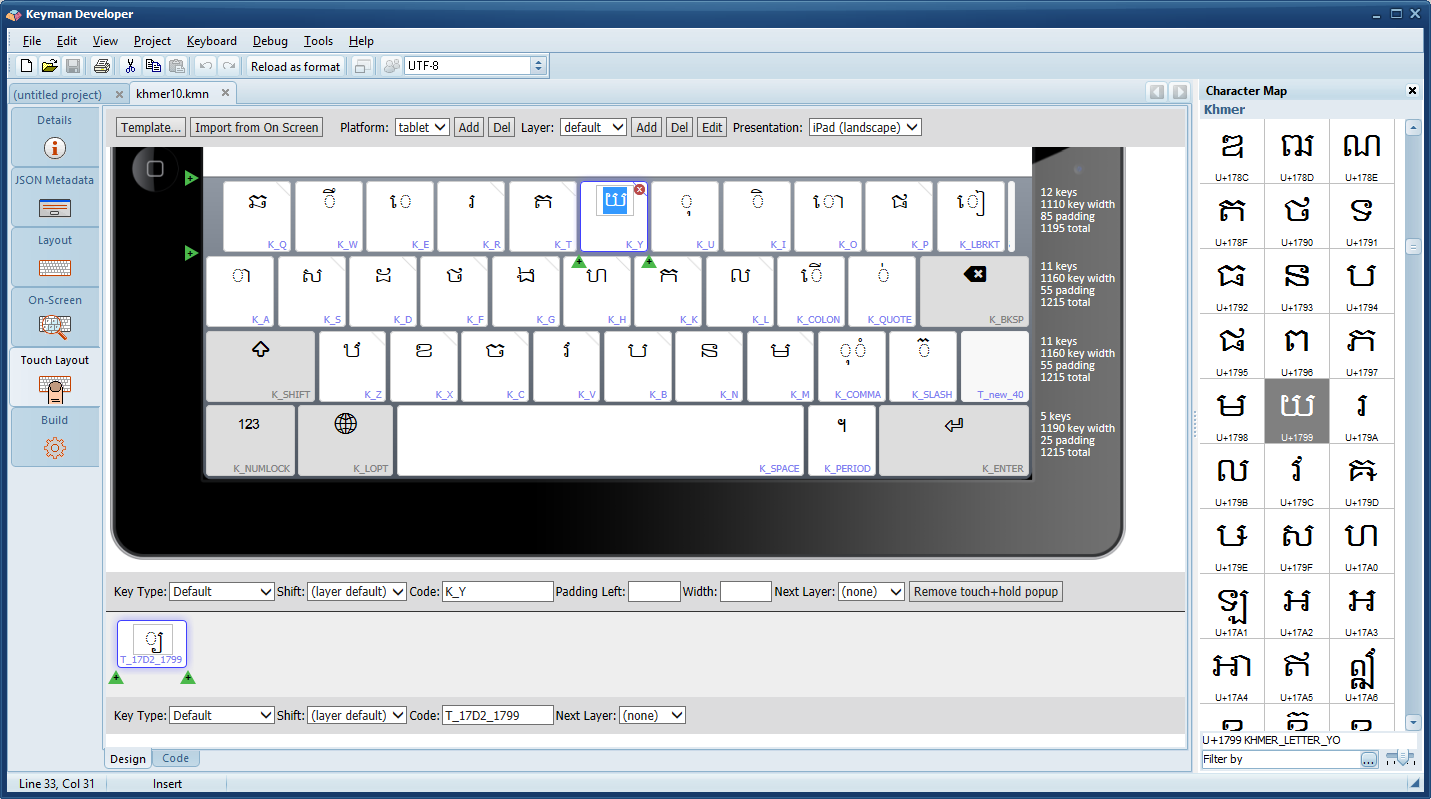
Keyman Developer makes it easy to play around with the layout of a keyboard and rapidly iterate the design. I was able to turn the original desktop layout into a mobile-optimised layout in under two hours, using only the visual editor.
The base keyboard comes from the khmer10 Keyman keyboard created by Andrew Cunningham, which is based on the NiDA Khmer keyboard layout. This is a desktop keyboard, which follows a phonetic-style input, with letters placed as far as possible on keys with a similar sound in the English alphabet. For example, ក is on the [k] key.
Design principles
I had a number of goals I wanted to achieve with this keyboard.
A design good for a language learner
I wanted the design to help me remember the script, the sounds and related letters. This may not be optimal for a person fluent in the language, but for me, the NiDA layout’s phonetic-style layout was a good starting point.
Reduce the number of keys …
As the original design is for a desktop keyboard, there are too many keys to fit on a normal mobile layout. As a mobile keyboard should ideally have no more than ten keys in a row, I started with reducing that as one goal.
… But don’t lose all relationship with the desktop keyboard
I tried to avoid moving keys around on the keyboard, or removing keys other than the ones described below. This way, once I do become familiar with the mobile layout, it is not a difficult transition to using the NiDA layout on a desktop computer.
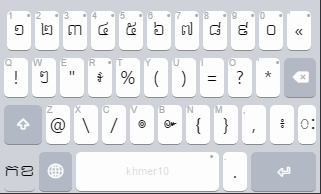
Move symbols and numbers off base layers
A number of non-alphabetic symbols are placed in a seemingly haphazard fashion on both the unshifted and Shift layers. The position of these symbols is probably pragmatic – the keys were available and not used for any other purpose. On a touch layout, we don’t need to maintain this because we can have as many or as few keys as we wish.
I moved all non-alphabetic symbols and numbers to a numeric/symbol layer.
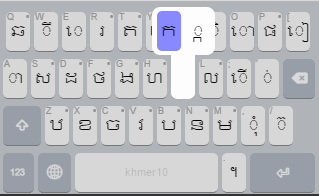
The original keyboard uses the key [j] as a prefix to create a sub consonant, by emitting the Unicode U+17D2 sub consonant marker character. This is a little obscure, and meant that the shapes of sub consonants were never visible on the keyboard.
I wanted to hide this encoding-based knowledge. I have added the sub consonants to the keyboard under a longpress menu for each base consonant, and added a rule to delete both the consonant and the prefix U+17D2 marker together when backspace is pressed. Thus, the average keyboard user need never know about the existence of U+17D2.
Independent vowels
As these are less frequently typed than the dependent vowels, they really didn’t need their own key on the keyboard. Again, from a language learner point of view, placing the independent vowels under the related dependent vowel symbol, as longpress menus, helps me to learn the shapes more rapidly. It also means that I don’t confuse the independent vowel shapes with similarly shaped consonants on the layout.
Adding missing characters
The Khmer digits were already on the keyboard, but the Hindu-Arabic numerals were not. I added these as long-press under the Khmer digit keys on the numeric/symbol layer.
Things that are not yet right
This keyboard is nowhere near finished, but it’s now at a good point to start using it, before making further optimisations. After using it for a while, I will have a clearer understanding of what is uncomfortable or awkward to use, and will also probably have better ideas of how to resolve the issues.
Some of the issues I already know about are:
Still too many keys per row: some rows have 12 keys. I should try to reduce this to 10 keys.
There are vowel combinations that may or may not be necessary. These do not render correctly on most operating systems on the keyboard, but do when used in writing.
The backspace key should be either on the top row, or on the third row. It’s only on the second row at present because that was where there was space!
The keyboard is missing a number of symbols that I probably won’t be using for now, but should be available for a complete solution, such as the Lek Attak numeric divination symbols. Some archaic letters are also not yet present.
The Khmer OS fonts do not use the dotted circle for isolated diacritics, which makes them hard to read on the keyboard.
The layers are not precisely the same width, which leads to slightly disconcerting movement on layer switches.
The shift key on the shift layer is missing its icon.
I just realised the independent vowels are currently missing – I need to re-add those soon!
Screenshot on Android:
Issues with using the keyboard include:
iOS has rendering bugs with Khmer, for example ខ្ញុំ on iOS overlaps the two subscript marks.
On Android, there are different rendering issues, for example the font is too large for the keys by default (showing the original keyboard as I don’t have an Android device handy for an up-to-date screenshot).
Get the keyboard + source
Despite these limitations, the keyboard should be usable for typing most Khmer text today, as least on iOS. It certainly covers most of my needs as a language learner today. As such, I’ve made it available for install into Keyman for iPhone and iPad or Keyman for Android.
First, install the app from the appropriate link above. Then click the link below to add the keyboard to your device. I haven’t included a font in the keyboard, so you’ll need a device which already supports rendering the script.
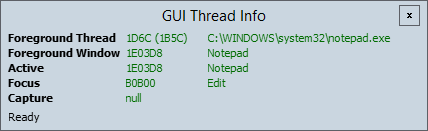
A very quick one today. GUIInfo is a tiny little utility that has a narrow purpose: it shows, in realtime, the current active, focus, foreground and capture window information for Windows.
Why this utility? Debugging focus issues is always frustrating. Attempting to observe current window focus information in a debugger results in the focus changing (to the debugger, of course). You can work around this – use remote debugging, or add logging in the debugger – but it’s a hassle.
Debugging focus issues would make Werner Heisenberg feel right at home.
Screenshot
Features
Updates 10 times a second so changes are reflected promptly.
Changes are highlighted in green, and slowly fade back to black.
Hovering over bold window labels will highlight the relevant window on the screen.
Topmost, so you can see the information without needing to try and keep the window visible.
Way way back in the dark ages of Delphi XE2, I wrote a function to encode components of a URI. Now, this function has been updated for use on mobile platforms, by Nicolas Dusart, and I quote Nicolas:
I had to make some modifications on it to compile for the mobile platforms, as the strings are 0-based on these platforms.
I also modified it to escape non-ASCII characters using their UTF-8 encoding as the standards advices. For multi-bytes characters, each byte is percent-encoded as usual.
Here’s the code, maybe it could interests you and the future readers of that article 🙂
And here’s Nicolas’s updated function in all its glory:
function EncodeURIComponent(const ASrc: string): string;
const
HexMap: string = '0123456789ABCDEF';
function IsSafeChar(ch: Byte): Boolean;
begin
if (ch >= 48) and (ch <= 57) then Result := True // 0-9
else if (ch >= 65) and (ch <= 90) then Result := True // A-Z
else if (ch >= 97) and (ch <= 122) then Result := True // a-z
else if (ch = 33) then Result := True // !
else if (ch >= 39) and (ch <= 42) then Result := True // '()*
else if (ch >= 45) and (ch <= 46) then Result := True // -.
else if (ch = 95) then Result := True // _
else if (ch = 126) then Result := True // ~
else Result := False;
end;
var
I, J: Integer;
Bytes: TBytes;
begin
Result := '';
Bytes := TEncoding.UTF8.GetBytes(ASrc);
I := 0;
J := Low(Result);
SetLength(Result, Length(Bytes) * 3); // space to %xx encode every byte
while I < Length(Bytes) do
begin
if IsSafeChar(Bytes[I]) then
begin
Result[J] := Char(Bytes[I]);
Inc(J);
end
else
begin
Result[J] := '%';
Result[J+1] := HexMap[(Bytes[I] shr 4) + Low(ASrc)];
Result[J+2] := HexMap[(Bytes[I] and 15) + Low(ASrc)];
Inc(J,3);
end;
Inc(I);
end;
SetLength(Result, J-Low(ASrc));
end;
Delphi XE2 and later versions have a robust theming system that has a frustrating flaw: the client width and height are not reliably preserved when the theme changes the border widths for dialog boxes.
For forms that are sizeable this is not typically a problem, but for dialogs laid out statically this can look really ugly, as shown in this Stack Overflow question.
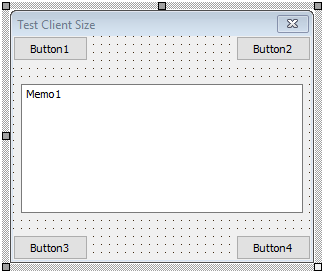
The problem in pictures
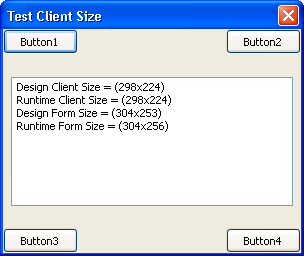
Here’s a little form, shown in the Delphi form designer. I’ve placed 4 buttons right in the corners of the form. I’m going to populate the Memo with notes on the form size at runtime.
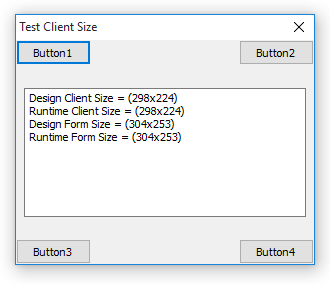
When I have no custom style set to the project (i.e. “Windows” style), I can run on a variety of platforms and see the buttons are where they should be. Shown here on Windows 10, Windows 7 and Windows XP (just because):
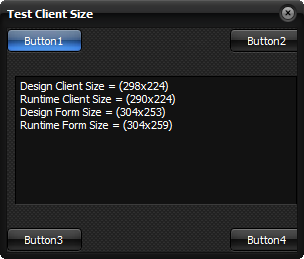
But when I apply a custom style to the project — I chose “Glossy” — then my dialog appears like so, instead:
You’ll note that the vertical is adjusted but the horizontal is not: Button2 and Button4 are now chopped off on the right. Because we are using themes, the form looks identical on all platforms.
For my needs, I found a workaround using a class helper, which can be applied to the forms which need to maintain their design-time ClientWidth and ClientHeight. This is typically the case for dialog boxes.
This workaround should be used with care as it has been designed to address a single issue and may have side effects.
It will trigger resize events at load time
Setting AutoScroll = true means that ClientWidth and ClientHeight are not stored in the form .dfm, and so this does not work.
It may not address other layout issues such as scaled elements scaling wrongly (I haven’t tested this).
type
TFormHelper = class helper for Vcl.Forms.TCustomForm
private
procedure RestoreDesignClientSize;
end;
procedure TfrmTestSize.FormCreate(Sender: TObject);
begin
RestoreDesignClientSize;
end;
{ TFormHelper }
procedure TFormHelper.RestoreDesignClientSize;
begin
if BorderStyle in [bsSingle, bsDialog] then
begin
if Self.FClientWidth > 0 then ClientWidth := Self.FClientWidth;
if Self.FClientHeight > 0 then ClientHeight := Self.FClientHeight;
end;
end;
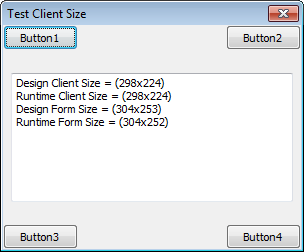
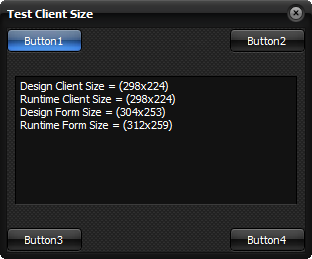
After adding in this little snippet, the form is now restored to its design-time size, like thus:
We just ran into a funny problem here, using a “tried and true” technique in SQL Server to concatenate strings. I use the quotes advisedly. This technique is often suggested on blogs and sites such as Stack Overflow, but we found out (by painful experience) that it is not to be relied on.
Update, 9 Mar 2016: Bruce Gordon from Webucator has turned this into a great little 5 minute video. Thanks Bruce! I don’t know anything much about Webucator, but they are doing some good stuff with creating well-attributed videos about blog posts such as this one and apparently they do SQL Server training.
The problem
So, given the following setup:
CREATE TABLE BadConcat (
BadConcatID INT NOT NULL,
Description NVARCHAR(100) NOT NULL,
SortIndex INT NOT NULL
CONSTRAINT PK_BadConcat PRIMARY KEY CLUSTERED (BadConcatID)
)
GO
INSERT BadConcat
SELECT 1, 'First Item', 1 union all
SELECT 2, 'Second Item', 2 union all
SELECT 3, 'Third Item', 3
GO
We need to concatenate those Descriptions. I have avoided fine tuning such as dropping the final comma or handling NULLs for the purpose of this example. This example shows one of the most commonly given answers to the problem:
DECLARE @Summary NVARCHAR(100) = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
ORDER BY ec.SortIndex
PRINT @Summary
And we get the following:
First Item, Second Item, Third Item,
And that works fine. However, if we want to include a WHERE clause, even if that clause still selects everything, then we suddenly get something weird:
SET @Summary = ''
SELECT @Summary = @Summary + ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
PRINT @Summary
Now we get the following:
Third Item,
What? What has SQL Server done? What’s happened to the first two items?
You’ll probably do what we did, which is to go through and make sure that you are selecting everything properly, which we are, and eventually come to the conclusion that “there must be a bug in SQL Server”.
You may encounter unexpected results when you apply any operators or expressions to the ORDER BY clause of aggregate concatenation queries.
Now, at first glance that does not directly apply. But we can extrapolate from that, as Microsoft developer support have done, in response to a bug report on SQL Server, to learn that:
The variable assignment with SELECT statement is a proprietary syntax (T-SQL only) where the behavior is undefined or plan dependent if multiple rows are produced
Using assignment operations (concatenation in this example) in queries with ORDER BY clause has undefined behavior. This can change from release to release or even within a particular server version due to changes in the query plan. You cannot rely on this behavior even if there are workarounds.
Some alternative solutions are given, also, in that second report:
The ONLY guaranteed mechanism are the following:
1. Use cursor to loop through the rows in specific order and concatenate the values
2. Use for xml query with ORDER BY to generate the concatenated values
3. Use CLR aggregate (this will not work with ORDER BY clause)
And the article “Concatenating Row Values in Transact-SQL” by Anith Sen goes through some of those solutions in detail. Sadly, none of them are as clean or as easy to understand as that original example.
Another example is given on Stack Overflow, which details how to safely use XML PATH to concatenate, without breaking on the XML special characters &, < and >. Applying that example into my problem code given above, we should use the following:
SELECT @Summary = (
SELECT ec.Description + ', '
FROM BadConcat ec
WHERE ec.BadConcatID in (1,2,3)
ORDER BY ec.SortIndex
FOR XML PATH(''), TYPE
).value('.','varchar(max)')
PRINT @Summary
We recently ran into a nasty little bug in the Delphi XE2 compiler, that arises with a complex set of conditions:
A record with a string property that has a get function;
A call to this getter that has a constant string appended to the result;
This result passed directly to another arbitrary function.
When these conditions are met (see code below for examples), the compiler generates code that crashes.
Reproducing the bug
The following program is enough to reproduce the bug.
program ustrcatbug;
type
TWrappedString = record
private
FValue: string;
function GetValue: string;
public
property Value: string read GetValue;
end;
{ TWrappedString }
function TWrappedString.GetValue: string;
begin
Result := FValue;
end;
function GetWrappedString: TWrappedString;
begin
Result.FValue := 'Something';
end;
begin
writeln(GetWrappedString.Value + ' Else');
end.
Looking at the last line of code from that sample in the disassembler, we see the following code:
The problem is that eax is not preserved through function calls with Delphi’s default register calling convention. And, as _UStrCat is a procedure, we can make no assumptions about the return value (which is passed in eax):
Upgrade to Delphi XE7 – this problem appears to be resolved, though I could not find a QC or RSP report relating to the bug when I searched. Moving to XE7 is not an option for us in the short term: too many code changes, too many unknowns.
Don’t use properties in records. This means changing code to call functions instead: no big deal for the Get, but annoying for the Set half of the function pair.
Patch around the problem by modifying UStrCat to return the address of the Dest parameter.
In the end, I wrote option (3) but we went with option (2) in our code base.
Because UStrCat is implemented in System.pas, it’s difficult to build your own version of the unit. One way to skin the option 3 UStrCat is to copy the implementation of UStrCat and its dependencies (a bunch of memory and string manipulation functions), and monkeypatch at runtime.
In the copied functions, we need to preserve eax through the function calls. This results in the addition of 4 lines of assembly to the UStrCat and UStrAsg functions, pushing the eax register onto the stack and popping it before exit. I haven’t reproduced the code here because the original is copyrighted to Embarcadero, but here are the changes required:
In UStrCat, Add push eax just after the conditional jump to UStrAsg, and pop eax just before the ret instruction.
In UStrAsg, wrap the call to FreeMem with a push eax and pop eax.
The patch function is also pretty straightforward:
procedure MonkeyPatch(OldProc, NewProc: PBYTE);
var
pBase, p: PBYTE;
oldProtect: Cardinal;
begin
p := OldProc;
pBase := p;
// Allow writes to this small bit of the code section
VirtualProtect(pBase, 5, PAGE_EXECUTE_WRITECOPY, oldProtect);
// First write the long jmp instruction.
p := pBase;
p^ := $E9; // long jmp opcode
Inc(p);
PDWord(p)^ := DWORD(NewProc) - DWORD(p) - 4; // address to jump to, relative to EIP
// Finally, protect that memory again now that we are finished with it
VirtualProtect(pBase, 5, oldProtect, oldProtect);
end;
function GetUStrCatAddr: Pointer; assembler;
asm
lea eax,System.@UStrCat
end;
initialization
MonkeyPatch(GetUStrCatAddr, @_UStrCatMonkey);
end.
This solution does give me the heebie jeebies, because we are patching the symptoms of the problem as we’ve seen them arise, without being able to either understand or address the root cause within the compiler. It’s not really possible to guarantee that there won’t be some other code path that causes this solution to come unstuck without really digging deep into the compiler’s code generation.
As noted, this problem appears to be resolved in Delphi XE5 or possibly earlier; however it is unclear if the root cause of the problem has been addressed, or we just got lucky. The issue has been reported as RSP-10255.
I read today Richard Ishida’s notes on his experiences displaying combining characters in a consistent way across browsers, and recalled with fondness the pain we have experienced with this, both in browsers and in apps, over many years.
When we design a keyboard layout for Keyman, we will often want to show a diacritic mark or combining character from a complex script by itself on a key cap, or show the mark with a substituted placeholder symbol that is distinct from the script itself, to show how the combining character fits with the base letter.
A commonly used placeholder symbol is ◌ U+25CC DOTTED CIRCLE, but there are others that are preferred for some languages.
I show below three attempts at presenting the combining marks on our Open Source KeymanWeb platform keyboards, running in Chrome on Windows 8.1. The first shows a Lao keyboard, with each of the combining characters presented around a base ກU+0E81 LAO LETTER KO on the keyboard. As you can see, this is not wonderful because the Ko Kai letter adds noise and makes it hard to pick out the combining characters.
Lao keyboard on keymanweb.com
The second keyboard is Thai. This relies on the system renderer and does not include a base character for the combining characters. In this case, that means that no base letter is shown and the marks show reasonably clearly. Unfortunately, this is not reliable across platforms, browsers or languages — it happens to work okay for Thai in Chrome on Windows 8.1. On some other systems, the combining marks are shifted to the far left of the key cap, or even off the key entirely.
Thai keyboard on keymanweb.com
The third keyboard example is for Gujarati, and again relies on the system renderer and does not include a base character for the combining characters. Now this time you see that the Uniscribe renderer on Windows 8.1 automatically inserts a dotted circle glyph — this may or may not be the same as the U+25CC character. Again, this behaviour differs across platforms.
Gujarati keyboard on keymanweb.com
The Story Today
The story today is pretty unfortunate. Display of isolated combining marks is not implemented at all consistently across the plethora of rendering engines, operating systems, browsers and fonts. Some systems will automatically insert a placeholder glyph if no conforming base character is found prior to the combining character. Others don’t. What do I mean by a conforming base character? Well, that’s up to the implementation of the renderer. Some renderers will treat any base character that is not in the same script as the combining character as part of a separate run, and won’t attempt to combine. Others will combine with some outside-script characters but not others.
Things get even worse when working with multiple combining characters without a base character. Unless this has been specifically handled in the renderer, you will typically see poor layout or rendering of the characters that may not be representative of how they form above normal base characters.
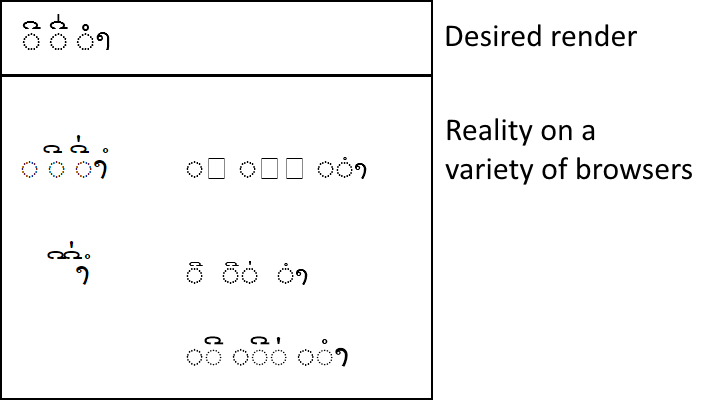
The image below shows examples of the marks U+0EB5 LAO VOWEL SIGN II, U+0EB5 LAO VOWEL SIGN II + U+0EC8 LAO TONE MAI EK and U+0EB3 LAO VOWEL SIGN AM, rendered with and without U+25CC DOTTED CIRCLE, on various systems. A more comprehensive set of examples is included later in this blog.
Sample Lao combining characters rendered
You can see, in the image above, examples of:
Repeated dotted circles
Diacritics that don’t align over their base character correctly
None of the basic text-only solutions work consistently across all systems.
It’s like stuffing a live octopus into a box
Attempting to address the problem is not fun. Fixing the problem on one browser/renderer/OS/font system invariably creates a new problem on another system. It’s like stuffing a live octopus into a box: each time you manage to get one of those pesky tentacles into the box, two others have snuck out the other side.
A Solution
We worked hard to find a consistent cross-browser solution. We started with Lao, but we believe that the same principles can be applied to other scripts. The solution relies on web fonts, but falls back to an acceptable solution in the shrinking subset of systems where web fonts are not supported.
We started by creating a font that is designed for use specifically with the On Screen Keyboard — it would never be used for presentation or editing. While at first glance this meant we could easily solve the problem by placing all the required marks into the Private Use Area, doing so would mean that on systems where the font was not available, the keyboard would be unusable.
Our final solutionhack uses the OpenType GSUB feature to replace the ກU+0E81 LAO LETTER KO with a placeholder mark when, and only when, it is used as a base character for a combining mark. The keyboard presentation code stores the Ko Kai letter as a base character for each combining character (or characters), and at render time the font substitutes its placeholder mark. When a key with this pair of characters is clicked, only the combining mark is displayed.
Lao keyboard with substituted base
Doing this means we can use the Ko Kai letter by itself on the keyboard (on the D key) without a problem (for example on its own key), and in the case where the special font is not available, the user will see an acceptable fallback with the Ko Kai letter as the base character for combining characters.
It’s worth noting that many renderers require that the placeholder character be the same font and style as the combining characters. Today, this sadly precludes using a different colour for the placeholder character.
Examples
I have collected screenshots from a variety of browsers that illustrate some of the inconsistencies and frustrations, as well as the happily correct rendering. You can also visit the sample page to see how well the rendering works in your system.
The screenshots include three combinations:
A simple single U+0EB5 LAO VOWEL SIGN II
A pair of diacritic marks U+0EB5 LAO VOWEL SIGN II + U+0EC8 LAO TONE MAI EK
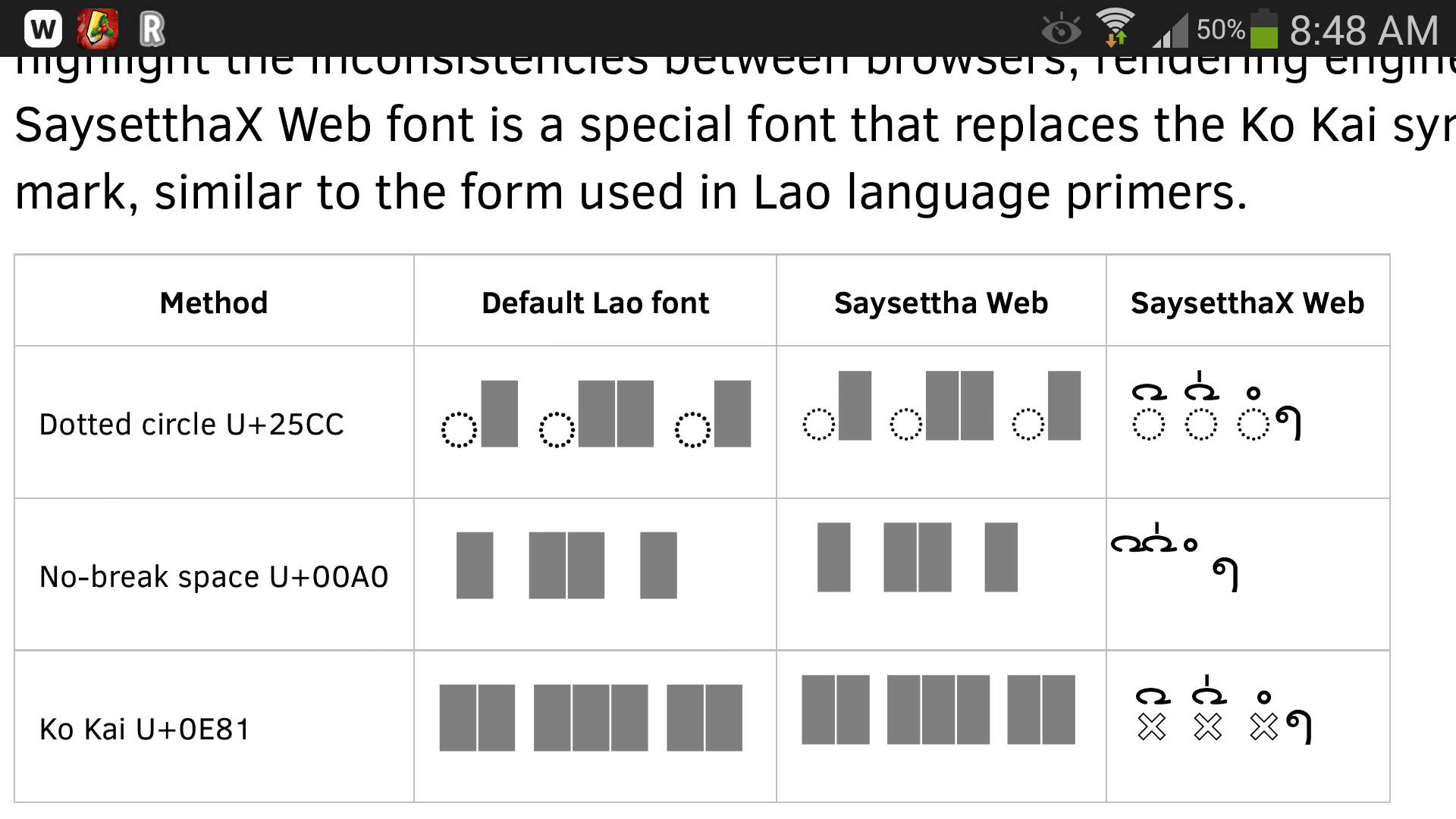
A third combining character U+0EB3 LAO VOWEL SIGN AM
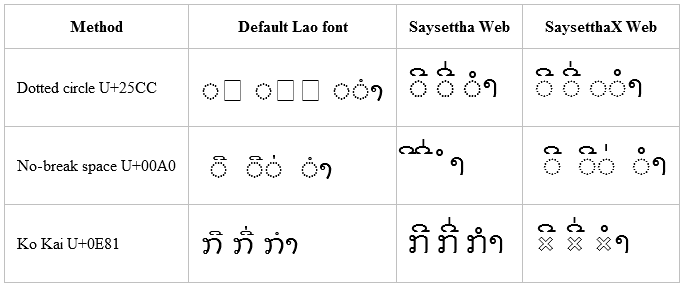
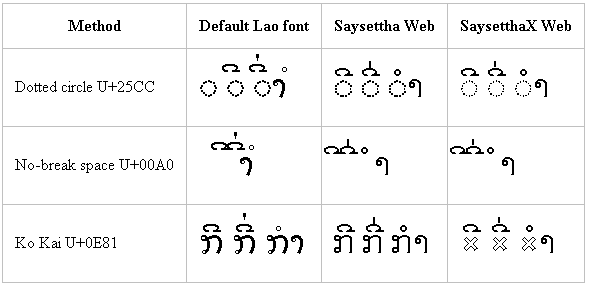
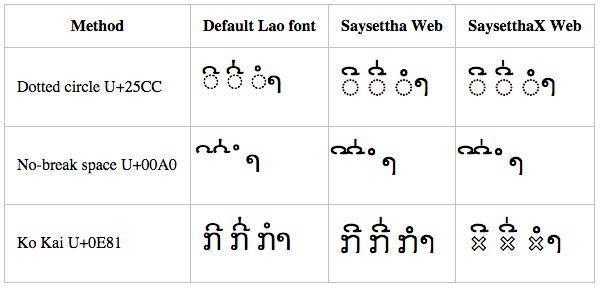
The sample shows these three combinations with the default font for the system, a Lao OpenType font “Saysettha Web”, and the special font “SaysetthaX Web” which has our hack in it, along with three different base characters: a hard-coded U+25CC DOTTED CIRCLE, a U+00A0 NO-BREAK SPACE, and a U+0E81 LAO LETTER KO.
Initially, the dotted circle with the Saysettha Web font looks hopeful. But in the end you will see that only one solution works on all browsers tested: the bottom right cell with the custom font and the Lao Letter Ko. The “hollow x” glyph that we use in this font is similar to the placeholder used in Lao language primers. However, any shape can of course be used here if you are creating your own font.
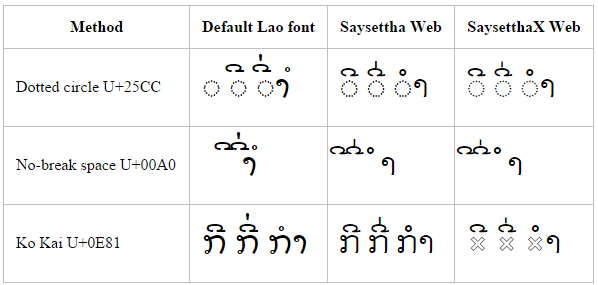
Windows 8.1 – Internet Explorer
Internet Explorer 11 on Windows 8.1 does surprisingly badly here — worse than earlier versions of Windows. Notice how the default Lao font (DokChampa) does not combine with dotted circle, nor does it combine the pair of diacritics correctly with no-break space.
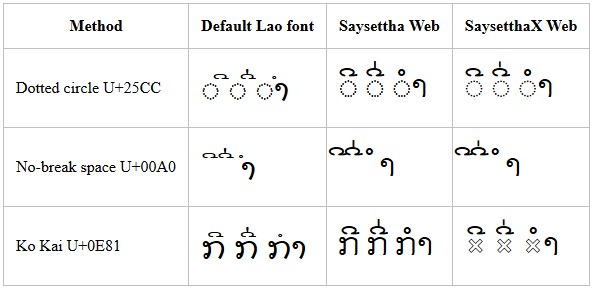
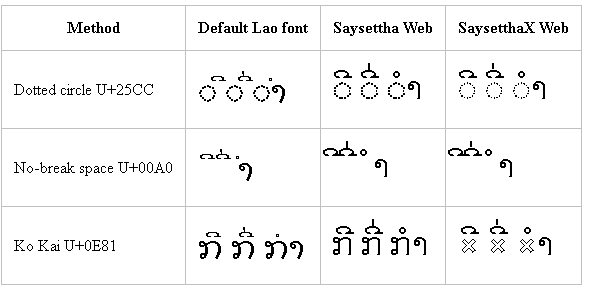
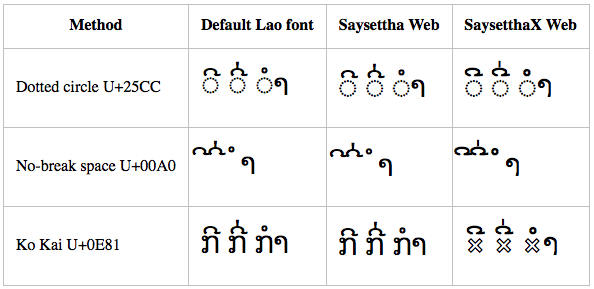
Windows 8.1 – Chrome
While Chrome stacks the pair of diacritics correctly in all cases, the positioning for Dok Champa relative to the base character is incorrect for both dotted circle and no-break space. You can also see how the Saysettha Web and SaysetthaX Web fonts position their diacritics to the left of the cell in the case of the no-break space.
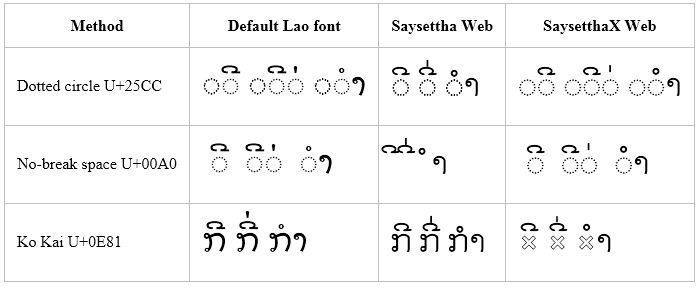
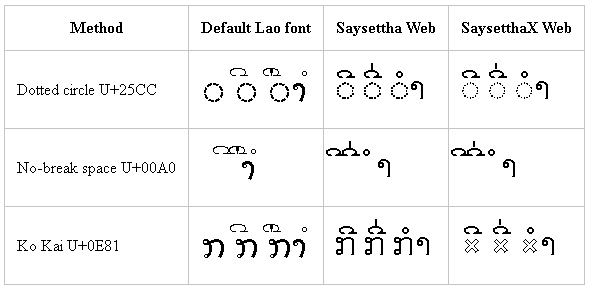
Windows 8.1 – Firefox
Firefox renderers similarly to Chrome. Note that it appears to be using Lao UI instead of DokChampa for the default font.
Windows 7 – Internet Explorer
Windows 7 – Chrome
(Font smoothing was not enabled on the remote connection when I captured the screenshot)
Windows 7 – Firefox
(Font smoothing was not enabled on the remote connection when I captured the screenshot)
Windows XP – Firefox
(Font smoothing was not enabled on the remote connection when I captured the screenshot)
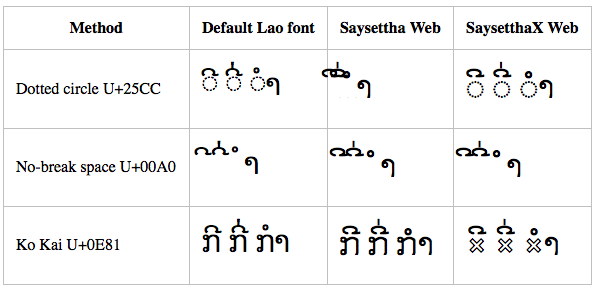
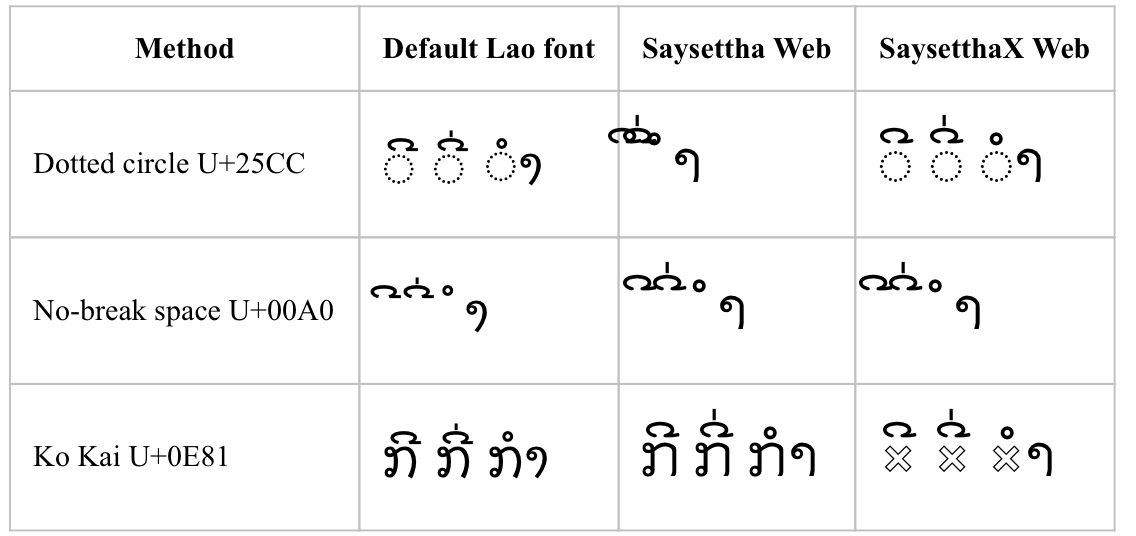
Mac OS X – Safari
Here we see the Saysettha Web solution with dotted circle, which worked consistently in Windows, fails in Mac OS X. Cross-platform support comes back to haunt us. Get back into that box, O tentacle!
Mac OS X – Chrome
Mac OS X – Firefox
It appears that Firefox is having trouble loading the Saysettha Web font, although the SaysetthaX Web font is loading, so this problem is probably resolvable.
iOS 8.1 – Safari
This is at least consistent with the situation in Safari on Mac OS X 10.8!
Windows Phone 8.1 – Internet Explorer
This is similar, but not identical to Internet Explorer 9 on Windows 7. That would be too easy!
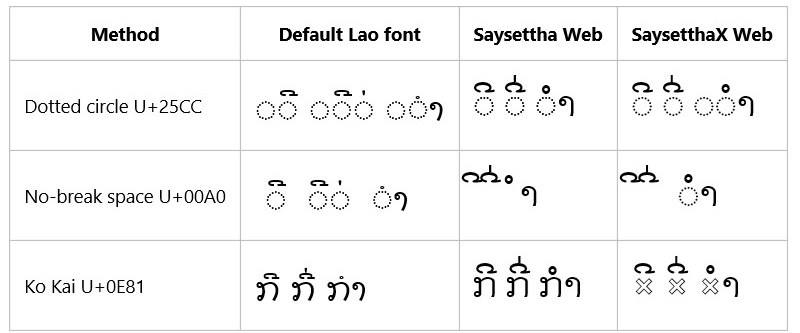
Android 4.3 – Android Browser
Clearly, no Lao font was available on the system, so the web fonts were the only ones that worked.
Android 4.3 – Chrome
Clearly, no Lao font was available on the system, so the web fonts were the only ones that worked.
Android 4.3 – Firefox
Clearly, no Lao font was available on the system. It also appears that Firefox is having trouble loading the Saysettha Web font, although the SaysetthaX Web font is loading, so this problem is probably resolvable.
Conclusion
In summary, the only solution today for on screen keyboards (or character pickers) that works consistently across all browsers is to create a custom font with what can only be classed as a hack, and supply that font for use within those pickers / on screen keyboards.
I certainly agree with Richard that a more formalised solution based on U+00A0 no-break space or U+25CC dotted circle would be fantastic.
After reading Abraham Polishchuk’s article AngularJS Performance in Large Applications, I wanted to dig a bit deeper on his suggestions before I took any of them on board. My basic concern was many of his suggestions seemed focused around technology-specific performance micro-optimisations. In today’s browser world, optimising around specific technologies (i.e. browsers and browser versions) is an expensive task with a limited life and usefulness: both improvements in the Javascript engines and differences in browser implementations mean that these fine-grained optimisations should really be limited to very specific performance critical situations.
Conversely, I don’t think we can expect Angular’s performance to improve in the same way as browser engines have. While Angular has undergone significant iterative performance improvements in the 1.x series, it is clear from the massive redesign of version 2.0 that most future application performance gains will only be won by rewriting significant chunks of your own code. Be aware!
Understanding computational complexity is crucial for web developers, even though with Angular it is all Javascript and browser and cloud and magic. You still need that software engineering education.
Onto the article.
1-2 Introduction, Tools of the Trade
No arguments here. Helpful.
3 Software Performance
Ok.
4.1 Loops
This advice, to move function calls out of loops, really depends on what the function you are calling is. Now, clearly, it’s sensible to move calls out of a loop if you can – that’s a normal O(n) to O(1) optimisation. And Objects.keys, as shown in the original article, is very heavy function, so that’d be a good one to avoid.
But don’t take this advice too far. The actual cost of the function call itself is minimal (http://jsperf.com/for-loop-perf-demo-basic/2). In general, inlining code to avoid a function call is not advisable: it results in less maintainable code for a minimal performance gain.
4.2 DOM access
While modifications to the DOM should be approached carefully, the reality is a web application is all about modifying the DOM, whether directly, or indirectly. It cannot be avoided! Applying inline styles (as opposed to using CSS selectors predefined in stylesheets?) vary significantly depending on both the styles being set and the browser. It’s certainly not a hard-and-fast rule, and not really a useful one. In the example, I compare background color (which should not force a reflow), and font-size (which would): (http://jsperf.com/inline-style-vs-class). The results vary dramatically across browsers.
4.3 Variable Scope and Garbage Collection
No arguments here. In fact I would go further and say that this is the single biggest performance concern, both in terms of CPU and resource usage, in Angular. In my limited experience, anyway. It’s very easy to leak closures without realising.
I would again urge you to avoid implementation-specific optimisations. Designing an application to minimize the number of properties in an object just because today’s implementation of V8 has a special internal representation of small objects is not good advice. Design your objects according to your application’s requirements! This is a good example of a premature optimizationantipattern.
This is a clear description of Angular scopes and the digest cycle. Good stuff. Abraham does a good job of unpacking the ‘magic’ of Angular.
6.1. Large Objects and Server Calls
Ok, so in my app I return full rows of data, and there are a few columns I don’t *currently* use in that data. I measured the performance impact on my application, and the cost of keeping those columns was insignificant: I was actually unable measure any difference. Again, this is a premature optimization antipattern. Your wins here will ultimately not be from excluding columns from your data but from making sure your data is normalized appropriately. This is about good design, rather than performance-constrained design.
Of course, there are plenty of other reasons to minimize your data across the wire. But remember that a custom serializer for each database object is another function to test, and another failure point. Measure the cost and the benefit.
6.2 Watching Functions
Yes. Never is a little too strong for me, but yeah, in general, avoid binding to functions.
6.3 Watching Objects
Yes, in general, deep watching of objects does introduce performance concerns. But I do not agree that this is a terrible idea. The alternative he gives (“relying on services and object references to propagate object changes between scopes”) gets pretty complicated and introduces maintenance and reliability concerns. I would approach this point as potential low hanging fruit for optimisation.
7.1 Long Lists
Yes.
7.2 Filters
As DJ commented, filters don’t work by hiding elements by CSS. Filters, as used in ng-repeat, return a transform of the array, which may be what Abraham meant?
7.3 Updating an ng-repeat
Pretty much. I would add that for custom syncing to work, you still need a unique key, just as you do for track by. If you are using Angular 1.3, there’s no benefit to the custom sync approach. Abraham has detailed the maintenance cost of custom syncing.
8. Rendering Problems
ng-if and ng-show are both useful tools. Choose your weapons wisely.
9.1 Bindings
Yes.
9.2 $digest() and $apply()
Yes, if you must. This is a great way to introduce inconsistencies in your application which can be very hard to debug!
9.3 $watch()
I really disagree with this advice. scope.$watch is a very practical way of separating concerns. I don’t think it’s indicative of bad architecture, quite the opposite in fact! While trying to find the discussions that Abraham refers to (but sadly doesn’t link to), it seemed that most of the alternatives given were in fact in themselves bad architecture. For example, Ben Lesh suggested (although he has since relaxed his opinion) using an ng-change on an input field instead of a watcher on the target variable. Why is that bad? From an architectural point of view, that means each place in your code that you change that variable, you have to remember to make that function call there as well. This is antithetical to the MVC pattern and seriously WET.
9.4 $on, $broadcast, and $emit
Apart from the advice to unbind $on(‘$destroy’) which I don’t think is correct, yes, being aware of the performance impact of events is important in an event-driven system. But that doesn’t mean don’t use them: events are a weapon to use wisely. Seeing a pattern here?
9.5 $destroy
Yes. Apart from the advice to “explicitly call your $on(‘$destroy’)” — I’m not sure what this means.
10.1 Isolate Scope and Transclusion
Only one quibble here: isolate scopes or transclusions can be faster than occupying the parent scope, because a tidy directive can use $apply to just update its own isolated scope, and avoid the digest of the entire scope tree. Choose your tools wisely.
10.2 The compile cycle
Basically, yes.
11 DOM Event Problems
Yes, addEventListener is more efficient, but so is not using Angular in the first place! This results in a significant code increase and again you the benefit of Angular in doing so. Going back to raw DOM is always a trade-off. In the majority of cases, the raw DOM event model is a whole lot of additional work for little gain.
12 Summary
In summary, I really think this post is about micro-optimisations that in many cases will not bring you the performance benefits you are looking for. Abraham’s summary suggests avoiding many of the most useful tools in Angular. If you have to roll your own framework code to avoid ng-repeat, or ng-click, you have already lost.